欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/ACL2, C++/F#/Lisp
Apache Cassandra
| |
您可以在Wikipedia上了解到此条目的英文信息 Apache Cassandra Thanks, Wikipedia. |
Apache Cassandra是一套开源分布式Key-Value存储系统。它最初由Facebook开发,用于储存特别大的数据。Facebook目前在使用此系统。


目录 |
理论基础
- peer-to-peer、环形架构基于 Amazon Dynamo
- 数据存储模型基于 Google BigTable
- Cassandra: Daughter of Dynamo and BigTable
- gossip protocol
- SEDA
主要特性
- 分布式
- 基于Column的结构化
- 高度可伸展性
2 nodes can handle 100,000 transactions per second, 4 nodes will support 200,000 transactions/sec and 8 nodes will tackle 400,000 transactions/sec。

Cassandra的主要特点就是它不是一个数据库,而是由一堆数据库节点共同构成的一个分布式网络服务,对Cassandra 的一个写操作,会被复制到其他节点上去,对Cassandra的读操作,也会被路由到某个节点上面去读取。对于一个Cassandra群集来说,扩展性能是比较简单的事情,只管在群集里面添加节点就可以了。
Cassandra是一个混合型的非关系型数据库,类似于Google的BigTable。其主要功能比 Dynomite(分布式的Key-Value存储系统)更丰富,但支持度却不如文档存储MongoDB(介于关系数据库和非关系数据库之间的开源产品,是非关系数据库当中功能最丰富,最像关系型数据库。支持的数据结构非常松散,是类似JSON的bjson格式,因此可以存储比较复杂的数据类型)Cassandra最初由Facebook开发,后转变成了开源项目。它是一个网络社交云计算方面理想的数据库。以Amazon专有的完全分布式的Dynamo为基础,结合了Google BigTable基于列族(Column Family)的数据模型。P2P去中心化的存储。很多方面都可以称之为Dynamo 2.0。
和其他数据库比较,有几个突出特点:
- 模式灵活:使用Cassandra,像文档存储,你不必提前解决记录中的字段。你可以在系统运行时随意的添加或移除字段。这是一个惊人的效率提升,特别是在大型部署上。
- 真正的可扩展性:Cassandra是纯粹意义上的水平扩展。为给集群添加更多容量,可以指向另一台电脑。你不必重启任何进程,改变应用查询,或手动迁移任何数据。
- 多数据中心识别:你可以调整你的节点布局来避免某一个数据中心起火,一个备用的数据中心将至少有每条记录的完全复制。
一些使Cassandra提高竞争力的其他功能:
- 范围查询:如果你不喜欢全部的键值查询,则可以设置键的范围来查询。
- 列表数据结构:在混合模式可以将超级列添加到5维。对于每个用户的索引,这是非常方便的。
- 分布式写操作:有可以在任何地方任何时间集中读或写任何数据。并且不会有任何单点失败。
版本
- 4.x
- 3.x:3.9, 3.9 javadoc
- 2.x
What’s New in Cassandra 2.2: JSON Support
- 1.x
指南
OS X
brew install cassandra brew info cassandra cassandra -f
bin/cassandra -f
bin/cqlsh
or cqlsh 1.2.3.4 9042 // ip, port
cqlsh> help
cqlsh> describe keyspaces;
cqlsh> use system;
cqlsh:system> select * from schema_keyspaces; // 所有keyspaces
cqlsh:system> describe schema_keyspaces; // schema_keyspaces所有表和表定义
cqlsh> CREATE KEYSPACE mykeyspace
... WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };
cqlsh> use mykeyspace;
cqlsh:mykeyspace> CREATE TABLE users (
... user_id int PRIMARY KEY,
... fname text,
... lname text
... );
cqlsh:mykeyspace> INSERT INTO users (user_id, fname, lname)
... VALUES (1745, 'john', 'smith');
cqlsh:mykeyspace> INSERT INTO users (user_id, fname, lname)
... VALUES (1744, 'john', 'doe');
cqlsh:mykeyspace> INSERT INTO users (user_id, fname, lname)
... VALUES (1746, 'john', 'smith');
cqlsh:mykeyspace> select * from users;
user_id | fname | lname
---------+-------+-------
1745 | john | smith
1744 | john | doe
1746 | john | smith
cqlsh:mykeyspace> select now(), uuid(), token() from mykeyspace.users;
Tools
cd apache-cassandra-2.1.8/tools/bin cassandra-stress help -schema cassandra-stress write n=1000000 // 写100万行 cassandra-stress read n=200000 // 读20万行 cassandra-stress write n=1000000 cl=one -mode native cql3 -schema keyspace="stress" -log file=~/load_1M_rows.log // 写入100万行 cqlsh:mykeyspace> select count(*) from stress.standard1; count --------- 1000000 cqlsh> describe stress.standard1; cqlsh> select * from stress.standard1 limit 10;
系统信息
nodetool --host 127.0.0.1 cfstats cqlsh> describe system; cqlsh> select * from system.batchlog; cqlsh> select * from system.compaction_history; cqlsh> select * from system.compactions_in_progress; cqlsh> select * from system.hints; cqlsh> select * from system.local; cqlsh> select * from system.peers; cqlsh> select * from system.peer_events; cqlsh> select * from system.range_xfers; cqlsh> select * from system.sstable_activity; cqlsh> select * from system.schema_columnfamilies; cqlsh> select * from system.schema_columns; cqlsh> select * from system.schema_triggers; cqlsh> select * from system.schema_usertypes; cqlsh> select * from system.size_estimates; cqlsh> select * from system.schema_keyspaces; cqlsh> select * from mykeyspace.users; cqlsh> select * from system_traces.sessions; cqlsh> select * from system_traces.events;
CQL
- Cassandra Query Language (CQL) v3
- CQL: This is not the SQL you are looking for
- CQL for Cassandra 2.x
CQL Java === ==== boolean java.lang.Boolean int java.lang.Integer bigint java.lang.Long float java.lang.Float double java.lang.Double inet java.net.InetAddress text java.lang.String ascii java.lang.String timestamp java.util.Date uuid java.util.UUID timeuuid java.util.UUID varint java.math.BigInteger decimal java.math.BigDecimal blob java.nio.ByteBuffer list<E> java.util.List<E> where E is also a type from this list set<E> java.util.Set<E> where E is also a type from this list map<K,V> java.util.Map<K,V> where K and V is also a types from this list (user type) com.datastax.driver.core.UDTValue (tuple type) com.datastax.driver.core.TupleValue
C++
ScyllaDB 是用 C++ 重写的 Apache Cassandra,完全兼容 Cassandra.
.NET
Python
sudo pip install ipython-cql sudo pip install virtualenvwrapper source /usr/local/bin/virtualenvwrapper.sh git clone https://github.com/rustyrazorblade/python-presentation cd python-presentation mkvirtualenv tutorial pip install -r requirements.txt ipython notebook
MariaDB
- MariaDB的Cassandra存储引擎 允许MariaDB通过标准SQL语法使用Cassandra集群。
- Cassandra Storage Engine
Docker
Spark
- Zen and the Art of Spark Maintenance
- DataStax Spark Cassandra Connector
- Installing the Cassandra / Spark OSS Stack
Presto
集群HA
控制台
- Priam (Netflix)
- cassandra-webconsole
- Cassandra Cluster Admin
- Virgil is a services layer for Cassandra
- Cassandra Snapshotter
- CTOP ("Top for Cassandra")
驱动
- Apache Cassandra Client Drivers
- Astyanax is a high level Java client for Apache Cassandra
- django-cassandra-engine - the Cassandra backend for Django
- Kundera
- pip install cassandra-driver // python
厂商
案例
目前,Cassandra对于Netflix而言是首选数据库,因为它们几乎满足了Netflix的所有需求。Netflix已经将95%的数据存储在Cassandra上,包括客户账户信息、影片评分、影片元数据、影片书签和日志等。Netflix在750多个节点上运行着50多个Cassandra集群。高峰时,Netflix每秒要处理50,000多个读取和100,000写入操作。Netflix平均每天要处理21亿次的读取与43亿次的写入操作。
- DataStax也为其他各种行业建立了不同版本的Cassandra工具。DataStax已经筹资8400万美元,目前有员工300多人,正准备IPO。埃利斯称,他们已经有500多家客户,包括“财富100强”中的25家大公司。
- 这款数据库曾被Facebook抛弃 现正帮苹果壮大 Apple's, with over 75,000 nodes storing over 10 PB of data.
- SoundCloud's Activity Feed and Real-Time Stats Powered by Apache Cassandra
- Facebook’s Instagram: Making the Switch to Cassandra from Redis, a 75% ‘Insta’ Savings
- Nexgate Chooses Cassandra over MongoDB for their Multi-Master NoSQL Solution
- Urban Airship Utilizing Cassandra to Connect Hundreds of Millions of Devices for Breaking News Alerts
- Apache Cassandra Powers Yakaz for 10 Million Unique Visitors Every Month
- i2O Water Switches to Cassandra from Microsoft SQL Server, Saving Over 100 Million Liters of Water per Day Across the World
- AppDynamics Utilizes Cassandra for App Monitoring and Metrics Tracking
- Coursera’s Adoption of Cassandra
- Spotify是怎样从Postgres切换至Cassandra的? Personalization at Spotify Using Apache Cassandra, Spotify scales to the top of the charts with Apache Cassandra at 40k requests/second
- RSA migrates from Oracle to Apache Cassandra to protect your online banking
- Gaming dev platform Unity powers up with Cassandra; migrates away from MongoDB for a scalable low latency solution
- Coursera migrates to the top of the class; moves their over 9 million students to Cassandra for an always on, on-demand classroom
- Multimedia messaging app Cubie is ready to grow, worry free, with Apache Cassandra
- Multi-Datacenter Cassandra on 32 Raspberry Pi’s
迁移
数据库迁移
- MySQL to Cassandra Migrations
- Oracle to Cassandra Migrations
- MongoDB to Cassandra Migrations
- HBase to Cassandra Migrations
- Redis to Cassandra Migrations
文档
- Delivering Meaning In NearReal Time At High Velocity & Massive Scale
- An Introduction to Real-Time Analytics with Cassandra and Hadoop
- Cassandra Data Modeling Best Practices at eBay Cassandra at eBay Cassandra Scale at eBay
图集

Column
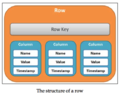
Row
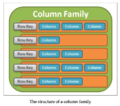
Column family
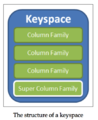
Keyspace
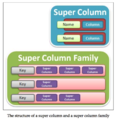
Super
CFS文件系统

虚拟节点
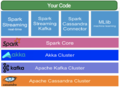
Cassandra+Kafka+Akka
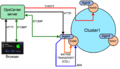
OpsCenter架构
DevCenter
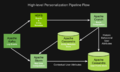
个性化推荐引擎
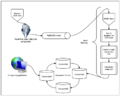
RabbitMQ-Storm-Cassandra实时分析
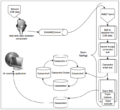
实时分析集成Esper
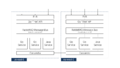
微服务平台
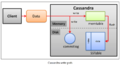
写路径
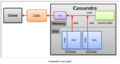
读路径
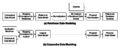
关系型和Cassandra

Cassandra中的表

与关系型对比
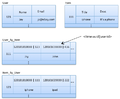
eBay用户模型
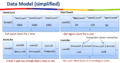
eBay用户模型
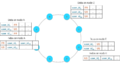
分布式索引
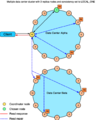
多数据中心一致性
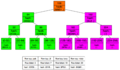
Gossip反熵算法
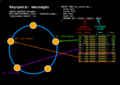
Keyspace
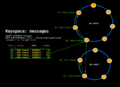
Keyspace多数据中心
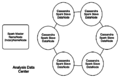
Cassandra+Spark分析数据中心
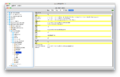
JConsole
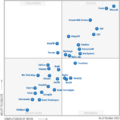
Gartner魔力象限
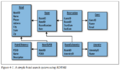
RDBMS模型

Cassandra模型
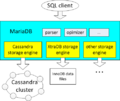
MariaDB存储引擎

Cassandra集群

Cassandra集群

Cassandra集群

Cassandra集群

































