欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/Agda, C++/Erlang/Lisp
Apache Flink
来自开放百科 - 灰狐
(版本间的差异)
小 (→图集) |
小 (→项目) |
||
| (未显示1个用户的8个中间版本) | |||
| 第15行: | 第15行: | ||
*性能卓越:性能卓越的批处理与流处理支持。 | *性能卓越:性能卓越的批处理与流处理支持。 | ||
*规模计算:作业可被分解成上千个任务,分布在集群中并发执行。 | *规模计算:作业可被分解成上千个任务,分布在集群中并发执行。 | ||
| + | |||
| + | ==FLIP== | ||
| + | [https://cwiki.apache.org/confluence/display/FLINK/Flink+Improvement+Proposals Flink Improvement Proposal (FLIP)] | ||
| + | |||
| + | ==Actor== | ||
| + | 使用了 [[Akka]],将 Flink 带入 Actor System。 | ||
| + | |||
| + | ==CEP== | ||
| + | [https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/libs/cep/ FlinkCEP] - [[Complex event processing]] for Flink | ||
| + | |||
| + | ==项目== | ||
| + | *[https://github.com/apache/flink/tree/blink Blink分支仓库] [https://www.oschina.net/news/104016/ali-blink-officially-open-source 阿里 Blink 正式开源,重要优化点解读] | ||
| + | *[https://github.com/apache/flink/tree/master/flink-runtime-web Apache Flink Web Dashboard] 使用 [[Angular]] 和 [https://github.com/NG-ZORRO/ng-zorro-antd NG-ZORRO] UI 组件 | ||
| + | |||
| + | ==用户== | ||
| + | [http://flink.apache.org/zh/poweredby.html Flink 用户] | ||
| + | *滴滴出行使用 Apache Flink 支持了实时监控、实时特征抽取、实时ETL等业务。 | ||
| + | *阿里巴巴(Alibaba)使用 Flink 的分支版本 Blink 来优化实时搜索排名。 | ||
| + | *快手使用了 Apache Flink 搭建了一个实时监控平台,监控短视频和直播的质量。 | ||
| + | *腾讯利用 Apache Flink 构建了一个内部平台,以提高开发和操作实时应用程序的效率。 | ||
| + | *Uber 在 Apache Flink 上构建了基于 SQL 的开源流媒体分析平台 AthenaX。 | ||
| + | *唯品会应用Flink实时的将数据流ETL到Hive中用于数据处理和分析 | ||
==文档== | ==文档== | ||
| 第29行: | 第51行: | ||
image:apache-flink-on-yarn.png|Flink on YARN | image:apache-flink-on-yarn.png|Flink on YARN | ||
image:apache-flink-process-model.png|进程模型 | image:apache-flink-process-model.png|进程模型 | ||
| + | image:apache-flink-plan-visualizer.png|Plan Visualization | ||
</gallery> | </gallery> | ||
==链接== | ==链接== | ||
*[http://flink.apache.org/ Apache Flink官网] | *[http://flink.apache.org/ Apache Flink官网] | ||
| − | *[https://flink- | + | *[https://www.flink-forward.org/ The Apache Flink Conference] |
| + | *[https://github.com/flink-china Apache Flink China] | ||
*[https://github.com/apache/flink Apache Flink @ GitHub] | *[https://github.com/apache/flink Apache Flink @ GitHub] | ||
*[http://www.infoq.com/cn/articles/hadoop-storm-samza-spark-flink 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink] | *[http://www.infoq.com/cn/articles/hadoop-storm-samza-spark-flink 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink] | ||
| + | *[https://www.flink-forward.org/ The Apache Flink Conference] | ||
[[category:big data]] | [[category:big data]] | ||
2021年8月18日 (三) 14:59的最后版本
Apache Flink:下一代大数据处理引擎,起源于 Stratosphere。
相似项目:Apache Spark
目录 |
[编辑] 简介
Apache Flink 是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。可部署在各种集群环境,对各种大小的数据规模进行快速计算。
- 统一的大数据分析和批计算引擎
- 统一的大数据分析和流计算引擎
- 统一的大数据分析和机器学习引擎
[编辑] 优势
Apache Flink 为用户提供了更强大的计算能力和更易用的编程接口
- 批流统一:Runtime 和 SQL 层批流统一,提供高吞吐低延时计算能力和更强大的SQL支持。
- 生态兼容:与 Hadoop Yarn / Apache Mesos / Kubernetes 集成,并且支持单机模式运行。
- 性能卓越:性能卓越的批处理与流处理支持。
- 规模计算:作业可被分解成上千个任务,分布在集群中并发执行。
[编辑] FLIP
Flink Improvement Proposal (FLIP)
[编辑] Actor
使用了 Akka,将 Flink 带入 Actor System。
[编辑] CEP
FlinkCEP - Complex event processing for Flink
[编辑] 项目
[编辑] 用户
- 滴滴出行使用 Apache Flink 支持了实时监控、实时特征抽取、实时ETL等业务。
- 阿里巴巴(Alibaba)使用 Flink 的分支版本 Blink 来优化实时搜索排名。
- 快手使用了 Apache Flink 搭建了一个实时监控平台,监控短视频和直播的质量。
- 腾讯利用 Apache Flink 构建了一个内部平台,以提高开发和操作实时应用程序的效率。
- Uber 在 Apache Flink 上构建了基于 SQL 的开源流媒体分析平台 AthenaX。
- 唯品会应用Flink实时的将数据流ETL到Hive中用于数据处理和分析
[编辑] 文档
[编辑] 图集

Flink

架构
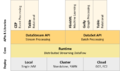
堆栈
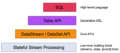
抽象级别

Flink在Hadoop生态中
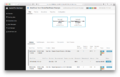
Dashboard
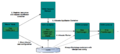
Flink on YARN
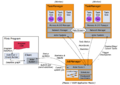
进程模型
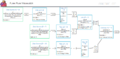
Plan Visualization








[编辑] 链接
分享您的观点