欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/Agda, C++/Erlang/Lisp
Apache Flink
来自开放百科 - 灰狐
Apache Flink:下一代大数据处理引擎,起源于 Stratosphere。
相似项目:Apache Spark
目录 |
简介
Apache Flink 是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。可部署在各种集群环境,对各种大小的数据规模进行快速计算。
- 统一的大数据分析和批计算引擎
- 统一的大数据分析和流计算引擎
- 统一的大数据分析和机器学习引擎
优势
Apache Flink 为用户提供了更强大的计算能力和更易用的编程接口
- 批流统一:Runtime 和 SQL 层批流统一,提供高吞吐低延时计算能力和更强大的SQL支持。
- 生态兼容:与 Hadoop Yarn / Apache Mesos / Kubernetes 集成,并且支持单机模式运行。
- 性能卓越:性能卓越的批处理与流处理支持。
- 规模计算:作业可被分解成上千个任务,分布在集群中并发执行。
文档
图集

架构
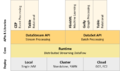
堆栈
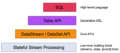
抽象级别

Flink在Hadoop生态中
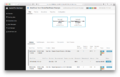
Dashboard
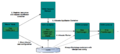
Flink on YARN
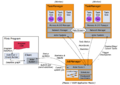
进程模型







链接
分享您的观点