欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/Agda, C++/Erlang/Lisp
Apache Hadoop
Apache Hadoop是一个软件平台,可以让你很容易地开发和运行处理海量数据的应用。Hadoop是MapReduce的开源实现,它使用了Hadoop分布式文件系统(HDFS)。MapReduce将应用切分为许多小任务块去执行。出于保证可靠性的考虑,HDFS会为数据块创建多个副本,并放置在群的计算节点中,MapReduce就在数据副本存放的地方进行处理
对于一个大文件,hadoop把它切割成一个个大小为64Mblock。这些block是以普通文件的形式存储在各个节点上的。默认情况下,每个block都会有3个副本。通过此种方式,来达到数据安全。就算一台机器down掉,系统能够检测,自动选择一个新的节点复制一份。
在hadoop中,有一个master node和多个data node。客户端执行查询之类的操作,只需与master node(也就是平时所说的元数据服务器)交互,获得需要的文件操作信息,然后与data node通信,进行实际数据的传输。
master(比如down掉)在启动时,通过重新执行原先的操作来构建文件系统的结构树。由于结构树是在内存中直接存在的,因此查询操作效率很高
核心:Hadoop Distributed File System
HBase: Bigtable-like structured storage for Hadoop HDFS

目录 |
新闻
简介
Hadoop Becomes the New core of the Analytical enterprise.
Apache Hadoop 是一种用于分布式存储和处理商用硬件上大型数据集的开源架构。Hadoop 可使企业迅速从海量的结构化和非结构化数据中获取洞察力。
版本
Hadoop的12个事实
- 事实1:Hadoop是由多个产品组成的。
- 事实2:Apache Hadoop是开源技术,但专有厂商也提供Hadoop产品。
- 事实3:Hadoop是一个生态系统,而非一个产品。
- 事实4:HDFS是文件系统,而不是数据库管理系统。
- 事实5:Hive与SQL类似,却非标准SQL。
- 事实6:Hadoop与MapReduce相互关联,但不相互依赖。
- 事实7:MapReduce提供的是对分析的控制,而不是分析本身。
- 事实8:Hadoop的意义不仅仅在于数据量,更在于数据的多样化。
- 事实9:Hadoop是数据仓库的补充,不是数据仓库的替代品。
- 事实10:Hadoop不仅仅是Web分析。
- 事实11:大数据不一定非Hadoop不可。
- 事实12:Hadoop不是“免费午餐”。
项目
- Awesome Big Data

- Awesome Hadoop
- Apache Avro 数据序列化
- Apache Cassandra 数据库
- Apache Chukwa 数据采集系统
- Apache HBase 数据库
- Apache Hive 数据仓库
- Apache Mahout 机器学习和数据挖掘
- Apache Pig 数据流语言
- Apache ZooKeeper 分布式协调服务
- Apache Hadoop Ozone uses Hadoop Distributed Data Storage (HDDS) for storage layer.
- Elasticsearch Hadoop
Quick Start
$ mkdir input $ cp conf/*.xml input $ bin/hadoop jar hadoop-*-examples.jar grep input output 'dfs[a-z.]+' $ cat output/*
Use the following conf/hadoop-site.xml:
<configuration>
<property>
<name>fs.default.name</name>
<value>localhost:9000</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Now check that you can ssh to the localhost without a passphrase:
$ ssh localhost
If you cannot ssh to localhost without a passphrase, execute the following commands:
$ ssh-keygen -t dsa -P -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
Format a new distributed-filesystem:
$ bin/hadoop namenode -format .... 08/03/19 11:15:41 INFO dfs.Storage: Storage directory /tmp/hadoop-allen/dfs/name has been successfully formatted.
Start The hadoop daemons:
$ bin/start-all.sh
Browse the web-interface for the NameNode and the JobTracker, by default they are available at:
NameNode - http://localhost:50070/ JobTracker - http://localhost:50030/
Copy the input files into the distributed filesystem:
$ bin/hadoop dfs -put conf input
Run some of the examples provided:
$ bin/hadoop jar hadoop-*-examples.jar grep input output 'dfs[a-z.]+'
Examine the output files:
Copy the output files from the distributed filesystem to the local filesytem and examine them:
$ bin/hadoop dfs -get output output $ cat output/*
or View the output files on the distributed filesystem:
$ bin/hadoop dfs -cat output/*
When you're done, stop the daemons with:
$ bin/stop-all.sh
Tutorial
- Writing An Hadoop MapReduce Program In Python
- Running Hadoop On Ubuntu Linux (Single-Node Cluster)
- Running Hadoop On Ubuntu Linux (Multi-Node Cluster)
Python
Projects
Developer
Yahoo

- Hadoop at Yahoo
- Yahoo! Distribution of Hadoop http://developer.yahoo.com/hadoop/
Powered By

We use Hadoop to store copies of internal log and dimension data sources and use it as a source for reporting/analytics and machine learning.Currently have around a hundred machines - low end commodity boxes with about 1.5TB of storage each. Our data sets are currently are of the order of 10s of TB and we routine process multiple TBs of data everyday.In the process of adding a 320 machine cluster with 2,560 cores and about 1.3 PB raw storage. Each (commodity) node will have 8 cores and 4 TB of storage.We are heavy users of both streaming as well as the Java apis. We have built a higher level data warehousing framework using these features (that we will open source at some point). We have also written a read-only FUSE implementation over hdfs.
>5000 nodes running Hadoop as of July 2007, biggest cluster: 2000 nodes (2*4cpu boxes w 3TB disk each), Used to support research for Ad Systems and Web Search. Also used to do scaling tests to support development of Hadoop on larger clusters
25 node cluster (dual xeon LV, 1TB/node storage), Used for charts calculation and web log analysis
up to 400 instances on Amazon EC2, data storage in Amazon S3
Using Hadoop to process apache log, analyzing user's action and click flow and the links click with any specified page in site and more. Using Hadoop to process whole price data user input with map/reduce.
More: http://wiki.apache.org/hadoop/PoweredBy
发行版
- Hortonworks Data Platform (HDP)
- Cloudera
- Mapr
- Apache Hadoop 软件的英特尔分发版
- Apache Bigtop构建Hadoop发行版
文档
- Apache Mesos + Apache YARN = Myriad
- From Oracle to Hadoop
- Apache Hadoop YARN: The Next generation Distributed Operating System
- Text Processing with Hadoop and Mahout: Key Concepts for Distributed NLP
- Hadoop 2 Cluster with Oracle Solaris Zones, ZFS, and Unified Archives
- An Introduction to Real-Time Analytics with Cassandra and Hadoop
图集

Hadoop 3.0

大数据

Architecture

Ecosystem
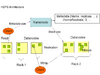
HDFS Architecture

Data Replication
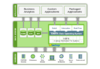
Hadoop数据架构

YARN架构中心
Docker镜像
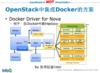
与OpenStack/Docker的融合

Spark和MapReduce

EDW Optimization
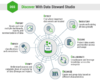
数据管家服务DSS
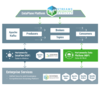
流消息管理器SMM

MapReduce















商业

- Hadoop for the Enterprise | Cloudera 已获得500万美元风投
- Dell开始销售打包Apache Hadoop解决方案 采用Cloudera分发版,运行在 Dell PowerEdge C2100 服务器和 Dell PowerConnect 6248 交换机上。
- Hortonworks Data Platform
博客
链接

- 华盛顿大学也从那时开始了一个以Hadoop为基础的分布式计算的课程
- Hadoop官网
- http://wiki.apache.org/hadoop/
- 伯克利AMPLab
- Yahoo's Hadoop Support
- 类似Google构架的开源项目Hadoop近获社区关注
- Structure Big Data揭示Hadoop未来:DataStax Brisk,EMC和MapReduce
- 用Hadoop搭建分布式存储和分布式运算集群
- Hadoop to run on EC2
- Run Your Own Google Style Computing Cluster with Hadoop and Amazon EC2
- Hadoop文档
- Hadoop中文文档
- Hadoop下载