欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/ACL2/Agda, C++/Lisp/Haskell
Pgpool
小 (→pgpool-II功能) |
|||
| (未显示1个用户的10个中间版本) | |||
| 第1行: | 第1行: | ||
| − | Pgpool | + | Pgpool 是一个 [[PostgreSQL]] 连接池和复制服务器,pgpool-II 是一个位于 PostgreSQL 服务器和 PostgreSQL 数据库客户端之间的中间件。 |
| − | [ | + | pgpool-II 使用 PostgreSQL 的前后台程序之间的协议,并且在前后台之间传递消息。 因此,一个(前端的)数据库应用程序认为 pgpool-II 就是实际的 PostgreSQL 数据库, 而后端的服务进程则认为 pgpool-II 是它的一个客户端。 因为 pgpool-II 对于服务器和客户端来说是透明的, 现有的数据库应用程序基本上可以不需要修改就可以使用 pgpool-II 了。 |
| − | ==pgpool- | + | |
| − | * | + | ==新闻== |
| − | * | + | *[http://www.pgpool.net/docs/pgpool-II-3.3.0/NEWS.txt pgpool-II 3.3.0 and pgpoolAdmin 3.3.0 officially released] |
| − | + | ||
| − | * | + | ==pgpool-II功能== |
| − | + | *伸缩性 | |
| − | + | 可扩展至128个数据库节点 | |
| + | |||
| + | *连接池 | ||
| + | pgpool-II 保持已经连接到 PostgreSQL 服务器的连接, 并在使用相同参数(例如:用户名,数据库,协议版本) 连接进来时重用它们。 它减少了连接开销,并增加了系统的总体吞吐量。 | ||
| + | |||
| + | *复制 | ||
| + | pgpool-II 可以管理多个 PostgreSQL 服务器。 激活复制功能并使在2台或者更多 PostgreSQL 节点中建立一个实时备份成为可能, 这样,如果其中一台节点失效,服务可以不被中断继续运行。 | ||
| + | |||
| + | *负载均衡 | ||
| + | 如果数据库进行了复制(可能运行在复制模式或者主备模式下),则在任何一台服务器中执行一个 SELECT 查询将返回相同的结果。 pgpool-II 利用了复制的功能以降低每台 PostgreSQL 服务器的负载。 它通过分发 SELECT 查询到所有可用的服务器中,增强了系统的整体吞吐量。 在理想的情况下,读性能应该和 PostgreSQL 服务器的数量成正比。 负载均很功能在有大量用户同时执行很多只读查询的场景中工作的效果最好。 | ||
| + | |||
| + | *连接限制 | ||
| + | PostgreSQL 会限制当前的最大连接数,当到达这个数量时,新的连接将被拒绝。 增加这个最大连接数会增加资源消耗并且对系统的全局性能有一定的负面影响。 pgpoo-II 也支持限制最大连接数,但它的做法是将连接放入队列,而不是立即返回一个错误。 | ||
| + | |||
| + | *并行查询 | ||
| + | 使用并行查询时,数据可以被分割到多台服务器上, 所以一个查询可以在多台服务器上同时执行,以减少总体执行时间。 并行查询在查询大规模数据的时候非常有效。 | ||
| + | |||
| + | ==Debian== | ||
| + | apt-get install pgpool2 | ||
| + | apt-get install postgresql-9.2-pgpool2 | ||
| + | |||
| + | ==图集== | ||
| + | <gallery> | ||
| + | image:pgpool-ii-arch.png|pgpool-II架构 | ||
| + | </gallery> | ||
| + | |||
| + | ==链接== | ||
| + | *[http://www.pgpool.net/ pgpool官网] | ||
*http://pgfoundry.org/projects/pgpool/ | *http://pgfoundry.org/projects/pgpool/ | ||
*http://pgpool.projects.postgresql.org/ | *http://pgpool.projects.postgresql.org/ | ||
| + | |||
| + | [[category:PostgreSQL]] | ||
2013年7月30日 (二) 13:54的最后版本
Pgpool 是一个 PostgreSQL 连接池和复制服务器,pgpool-II 是一个位于 PostgreSQL 服务器和 PostgreSQL 数据库客户端之间的中间件。
pgpool-II 使用 PostgreSQL 的前后台程序之间的协议,并且在前后台之间传递消息。 因此,一个(前端的)数据库应用程序认为 pgpool-II 就是实际的 PostgreSQL 数据库, 而后端的服务进程则认为 pgpool-II 是它的一个客户端。 因为 pgpool-II 对于服务器和客户端来说是透明的, 现有的数据库应用程序基本上可以不需要修改就可以使用 pgpool-II 了。
目录 |
[编辑] 新闻
[编辑] pgpool-II功能
- 伸缩性
可扩展至128个数据库节点
- 连接池
pgpool-II 保持已经连接到 PostgreSQL 服务器的连接, 并在使用相同参数(例如:用户名,数据库,协议版本) 连接进来时重用它们。 它减少了连接开销,并增加了系统的总体吞吐量。
- 复制
pgpool-II 可以管理多个 PostgreSQL 服务器。 激活复制功能并使在2台或者更多 PostgreSQL 节点中建立一个实时备份成为可能, 这样,如果其中一台节点失效,服务可以不被中断继续运行。
- 负载均衡
如果数据库进行了复制(可能运行在复制模式或者主备模式下),则在任何一台服务器中执行一个 SELECT 查询将返回相同的结果。 pgpool-II 利用了复制的功能以降低每台 PostgreSQL 服务器的负载。 它通过分发 SELECT 查询到所有可用的服务器中,增强了系统的整体吞吐量。 在理想的情况下,读性能应该和 PostgreSQL 服务器的数量成正比。 负载均很功能在有大量用户同时执行很多只读查询的场景中工作的效果最好。
- 连接限制
PostgreSQL 会限制当前的最大连接数,当到达这个数量时,新的连接将被拒绝。 增加这个最大连接数会增加资源消耗并且对系统的全局性能有一定的负面影响。 pgpoo-II 也支持限制最大连接数,但它的做法是将连接放入队列,而不是立即返回一个错误。
- 并行查询
使用并行查询时,数据可以被分割到多台服务器上, 所以一个查询可以在多台服务器上同时执行,以减少总体执行时间。 并行查询在查询大规模数据的时候非常有效。
[编辑] Debian
apt-get install pgpool2 apt-get install postgresql-9.2-pgpool2
[编辑] 图集
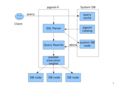
pgpool-II架构
