欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/ACL2/Agda, C++/Lisp/Haskell
Apache Calcite
来自开放百科 - 灰狐
(版本间的差异)
(以“Apache Calcite 是面向Hadoop新的查询引擎,它提供了标准的SQL语言。通过 [Adapters],提供对 Apache Cassandra 和 [[MongoD...”为内容创建页面) |
小 (→图集) |
||
| (未显示1个用户的10个中间版本) | |||
| 第1行: | 第1行: | ||
| − | Apache Calcite 是面向[[Apache | + | Apache Calcite 是面向 [[Apache Hadoop]] 新的查询引擎,它提供了标准的SQL语言。通过 [http://calcite.apache.org/docs/adapter.html Adapters],支持对 [[Apache Cassandra]] 和 [[MongoDB]] 等数据库的SQL查询。 |
==简介== | ==简介== | ||
| − | Calcite目标:是“one size fits | + | The foundation for your next high-performance database. |
| + | |||
| + | Calcite目标:是“one size fits all(一种方案适应所有应用场景)”,希望能为不同计算平台和数据源提供统一的查询引擎,并以类似传统数据库的访问方式(SQL和高级查询优化)来访问Hadoop上的数据。 | ||
Calcite是一种动态数据管理系统,它具有标准SQL、连接不同前端和后端、可定制的逻辑规划器、物化视图、多维数据分析和流查询等诸多能力,使其成为大数据领域中非常有吸引力的查询引擎,目前它已经或被规划集成到Hadoop的诸多项目中,比如Lingual (Cascading项目的SQL接口)、[[Apache Drill]]、[[Apache Hive]]、[[Apache Kylin]]、[[Apache Phoenix]]、[[Apache Samza]]和[[Apache Flink]]。 | Calcite是一种动态数据管理系统,它具有标准SQL、连接不同前端和后端、可定制的逻辑规划器、物化视图、多维数据分析和流查询等诸多能力,使其成为大数据领域中非常有吸引力的查询引擎,目前它已经或被规划集成到Hadoop的诸多项目中,比如Lingual (Cascading项目的SQL接口)、[[Apache Drill]]、[[Apache Hive]]、[[Apache Kylin]]、[[Apache Phoenix]]、[[Apache Samza]]和[[Apache Flink]]。 | ||
| + | |||
| + | Apache Calcite由[[Hortonworks]]和[[mapr|MapR]][http://calcite.apache.org/community/ 主导开发]。 | ||
==特性== | ==特性== | ||
* 支持标准SQL语言; | * 支持标准SQL语言; | ||
* 独立于编程语言和数据源,可以支持不同的前端和后端; | * 独立于编程语言和数据源,可以支持不同的前端和后端; | ||
| − | * [ | + | * [http://calcite.apache.org/docs/algebra.html 关系代数]是Calcite的核心,任何一个查询都可以表示成由关系运算符组成的树; |
* 支持关系代数、可定制的逻辑规划规则和基于成本模型优化的查询引擎; | * 支持关系代数、可定制的逻辑规划规则和基于成本模型优化的查询引擎; | ||
* 支持物化视图(materialized view)的管理(创建、丢弃、持久化和自动识别); | * 支持物化视图(materialized view)的管理(创建、丢弃、持久化和自动识别); | ||
| 第18行: | 第22行: | ||
==图集== | ==图集== | ||
| + | <gallery> | ||
| + | image:powered-by-apache-calcite.png|生态系统 | ||
| + | image:apache-calcite-avatica-architecture.png|Avatica | ||
| + | </gallery> | ||
==链接== | ==链接== | ||
| 第26行: | 第34行: | ||
[[category:cassandra]] | [[category:cassandra]] | ||
[[category:mongoDB]] | [[category:mongoDB]] | ||
| + | [[category:big data]] | ||
| + | [[category:data analysis]] | ||
| + | [[category:java]] | ||
| + | [[category:apache]] | ||
| + | [[category:hortonworks]] | ||
2018年10月2日 (二) 16:32的最后版本
Apache Calcite 是面向 Apache Hadoop 新的查询引擎,它提供了标准的SQL语言。通过 Adapters,支持对 Apache Cassandra 和 MongoDB 等数据库的SQL查询。
目录 |
[编辑] 简介
The foundation for your next high-performance database.
Calcite目标:是“one size fits all(一种方案适应所有应用场景)”,希望能为不同计算平台和数据源提供统一的查询引擎,并以类似传统数据库的访问方式(SQL和高级查询优化)来访问Hadoop上的数据。
Calcite是一种动态数据管理系统,它具有标准SQL、连接不同前端和后端、可定制的逻辑规划器、物化视图、多维数据分析和流查询等诸多能力,使其成为大数据领域中非常有吸引力的查询引擎,目前它已经或被规划集成到Hadoop的诸多项目中,比如Lingual (Cascading项目的SQL接口)、Apache Drill、Apache Hive、Apache Kylin、Apache Phoenix、Apache Samza和Apache Flink。
Apache Calcite由Hortonworks和MapR主导开发。
[编辑] 特性
- 支持标准SQL语言;
- 独立于编程语言和数据源,可以支持不同的前端和后端;
- 关系代数是Calcite的核心,任何一个查询都可以表示成由关系运算符组成的树;
- 支持关系代数、可定制的逻辑规划规则和基于成本模型优化的查询引擎;
- 支持物化视图(materialized view)的管理(创建、丢弃、持久化和自动识别);
- 基于物化视图的Lattice和Tile机制,以应用于OLAP分析;
- 支持对流数据的查询。
[编辑] 指南
[编辑] 图集

生态系统
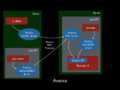
Avatica


[编辑] 链接
分享您的观点