欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/ACL2/Agda, C++/Lisp/Haskell
Search engine
小 (→链接) |
|||
| (未显示5个用户的61个中间版本) | |||
| 第1行: | 第1行: | ||
| − | + | "聚类" 是目前搜索引擎最热门的技术。 | |
| + | |||
| + | "聚类" 主要分为"搜索内容聚类"和"搜索结果排序聚类" | ||
| + | |||
| + | 搜索内容聚类:指基于内容方面的聚类 | ||
| + | |||
| + | 搜索结果排序聚类:主要体现在查询结果的排序上 | ||
| + | |||
| + | 国内著名搜索引擎公司百度总裁李彦宏说:搜索引擎不是人人都能做的领域,进入的门槛比较高。 | ||
[[Image:search_engine.jpg|thumb|right|典型的搜索引擎系统架构图]] | [[Image:search_engine.jpg|thumb|right|典型的搜索引擎系统架构图]] | ||
搜索引擎的门槛主要是技术门槛,包括网页数据的快速采集、海量数据的索引和存储、搜索结果的相关性排序、搜索效率的毫秒级要求、分布式处理和负载均衡、自然语言的理解技术等等,这些都是搜索引擎的门槛。 | 搜索引擎的门槛主要是技术门槛,包括网页数据的快速采集、海量数据的索引和存储、搜索结果的相关性排序、搜索效率的毫秒级要求、分布式处理和负载均衡、自然语言的理解技术等等,这些都是搜索引擎的门槛。 | ||
| − | [[ | + | 搜索引擎的策略都是采用[[Search Engine Technology|服务器群集和分布式计算技术]]。 |
| − | + | ||
| − | + | ||
经典文章: [http://infolab.stanford.edu/~backrub/google.html The Anatomy of a Large-Scale Hypertextual Web Search Engine] | 经典文章: [http://infolab.stanford.edu/~backrub/google.html The Anatomy of a Large-Scale Hypertextual Web Search Engine] | ||
| + | [[Image:Celestial-680x100.jpg|搜索互联网之外的秘密|right]] | ||
| + | ==搜索原理== | ||
| + | {{SeeWikipedia}} | ||
| + | 主要做三个步骤:从互联网上抓取网页 → 建立索引数据库 → 在索引数据库中搜索排序。 | ||
| + | |||
| + | 从互联网上抓取网页——利用能够从互联网上自动收集网页的Spider系统程序,自动访问互联网,并沿着任何网页中的所有URL爬到其它网页,重复这过程,并把爬过的所有网页收集回来。建立索引数据库——由分析索引系统程序对收集回来的网页进行分析,提取相关网页信息(包括网页所在URL、编码类型、页面内容包含的关键词、关键词位置、生成时间、大小、与其它网页的链接关系等),根据一定的相关度算法进行大量复杂计算,得到每一个网页针对页面内容中及超链中每一个关键词的相关度(或重要性),然后用这些相关信息建立网页索引数据库。在索引数据库中搜索排序——当用户输入关键词搜索后,由搜索系统程序从网页索引数据库中找到符合该关键词的所有相关网页。因为所有相关网页针对该关键词的相关度早已算好,所以只需按照现成的相关度数值排序,相关度越高,排名越靠前。最后,由页面生成系统将搜索结果的链接地址和页面内容摘要等内容组织起来返回给用户。 | ||
| + | |||
| + | ==搜索市场== | ||
| + | 据业内分析,今后以百度、Google和雅虎为主的水平搜索的增长将趋缓,而垂直搜索(手机移动搜索)、论坛搜索、本地搜索等未来新兴搜索引擎市场将以30%左右的速度增长,到2010年规模将达到78亿元。 | ||
| + | |||
| + | 也就是说,水平搜索风光不再,而垂直搜索则方兴未艾,垂直搜索是搜索市场新的“蓝海”。据市场研究机构Kelsey Group预测,在未来5年内,仅美国国内地区搜索市场规模将达34亿美元。 | ||
| + | |||
| + | ==搜索历史== | ||
| + | *[[Search Engine History|搜索引擎的历史]] | ||
==搜索引擎== | ==搜索引擎== | ||
| + | [[Image:searchmash.gif|right|thumb|http://www.searchmash.com]] | ||
| + | [[Image:powerset_title.jpg|right|thumb|http://www.powerset.com]] | ||
| + | [[Image:wisenut-system-architecture.gif|right|thumb|Wisenut System Architecture]] | ||
*[[List of search engines]] | *[[List of search engines]] | ||
*[[Google]] - http://www.google.com | *[[Google]] - http://www.google.com | ||
| 第16行: | 第39行: | ||
*http://www.chacha.com/ | *http://www.chacha.com/ | ||
*http://www.clusty.com | *http://www.clusty.com | ||
| + | *http://www.search.com | ||
*[[Autonomy]] - http://www.autonomy.com.cn | *[[Autonomy]] - http://www.autonomy.com.cn | ||
*[[WiseNut]] - http://www.wisenut.com/ | *[[WiseNut]] - http://www.wisenut.com/ | ||
| 第42行: | 第66行: | ||
==开源项目== | ==开源项目== | ||
| + | [[Image:wordID.jpg|thumb|right|搜索关键字处理流程]] | ||
| + | *[[Tesseract OCR]] - http://sourceforge.net/projects/tesseract-ocr | ||
| + | *[https://www.opensemanticsearch.org/ Open Semantic Search] | ||
| + | |||
| + | ===Spider=== | ||
| + | *[[Larbin]] | ||
| + | *[[OpenWebSpider]] | ||
| + | *[[Sphider]] | ||
| + | *[http://www.bigdata-madesimple.com/top-50-open-source-web-crawlers-for-data-mining/ Top 50 open source web crawlers for data mining] | ||
| + | |||
| + | ==Indexing== | ||
| + | *[[Snowball]] | ||
| + | *[[Stemmers]] | ||
| + | ===C,C++=== | ||
| + | *[[Larbin]] | ||
| + | *[[Apache Lucene4c]] | ||
| + | *[[CLucene]] is a C++ port of Lucene - http://clucene.sourceforge.net | ||
| + | *[[Swishpp|SWISH++]] - http://swishplusplus.sourceforge.net/ | ||
| + | *[[ht://Dig]] | ||
| + | *[[Larbin]] | ||
*[[mnoGoSearch]] - http://mnogosearch.org/ | *[[mnoGoSearch]] - http://mnogosearch.org/ | ||
| + | *[[Sphinx]] | ||
| + | *[[SF FTP Search Engine|SF超高速FTP搜索引擎]] | ||
| + | *[[Aspseek]] - http://www.aspseek.org/ | ||
| + | *[[OpenFTS]] - http://openfts.sourceforge.net/ | ||
| + | *[[Swish-e]] - http://www.swish-e.org/ | ||
| + | *[[OpenWebSpider]] - http://www.openwebspider.org/ | ||
| + | *[[DataparkSearch]] - http://www.dataparksearch.org/ | ||
| + | *[[Managing Gigabytes]] - http://www.cs.mu.oz.au/mg/ | ||
| + | *[[Namazu]](a Full-Text Search Engine) - http://www.namazu.org/index.html.en (include perl) | ||
| + | *[[Zebra]] - http://indexdata.dk/zebra/ | ||
| + | *[[Webglimpse]] - http://webglimpse.net/ | ||
| + | *[[Xapian]] - http://www.xapian.org/ | ||
| + | *[[Webbot]] | ||
| + | |||
| + | ===Python=== | ||
| + | *[[GrassyKnoll]] | ||
| + | ===Java=== | ||
*[[Apache Lucene]] Search Engine (no crawler) - http://lucene.apache.org | *[[Apache Lucene]] Search Engine (no crawler) - http://lucene.apache.org | ||
| − | |||
*[[Apache Nutch]] (open source web-scalable search engine) - http://lucene.apache.org/nutch/ | *[[Apache Nutch]] (open source web-scalable search engine) - http://lucene.apache.org/nutch/ | ||
*[[Apache Hadoop]] - http://lucene.apache.org/hadoop/ | *[[Apache Hadoop]] - http://lucene.apache.org/hadoop/ | ||
| − | * | + | *[[Heritrix]] |
| − | * | + | *[[Compass]] |
*JXTA Search - http://search.jxta.org/ | *JXTA Search - http://search.jxta.org/ | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
*[[XQEngine]](XML Query Engine) - http://xqengine.sourceforge.net/ | *[[XQEngine]](XML Query Engine) - http://xqengine.sourceforge.net/ | ||
| − | *[[ | + | *[[Web-Harvest]] |
| − | * | + | *[[YaCy]] |
| + | |||
| + | ===Ruby=== | ||
| + | *[[Ferret]] | ||
| + | ===PHP=== | ||
*[[Sphider]] | *[[Sphider]] | ||
| + | |||
| + | ===Perl=== | ||
==中文资源== | ==中文资源== | ||
*搜索引擎研究 - http://www.wespoke.com/ | *搜索引擎研究 - http://www.wespoke.com/ | ||
| + | *[http://docs.huihoo.com/infoq/this-is-search-engine.pdf 这就是搜索引擎:核心技术详解] | ||
==相关文章== | ==相关文章== | ||
| 第74行: | 第132行: | ||
*[[Search Engine and Web Crawler|中文搜索引擎技术揭密: 网络蜘蛛]] | *[[Search Engine and Web Crawler|中文搜索引擎技术揭密: 网络蜘蛛]] | ||
*[[Search Engine and System Structure|中文搜索引擎技术揭密:系统架构]] | *[[Search Engine and System Structure|中文搜索引擎技术揭密:系统架构]] | ||
| − | *[http://www-128.ibm.com/developerworks/cn/linux/l-spider/ 在 Linux 上构建 Web spider] | + | *[http://www-128.ibm.com/developerworks/cn/linux/l-spider/ 在 Linux 上构建 Web spider] |
| + | *[http://china-news-it.blogspot.com/2007/04/blog-post_7361.html 中文/英文搜索引擎推广登录入口 ] | ||
| + | *[http://china-news-it.blogspot.com/2007/04/chinese-search-engine-situation.html 2006chinese search engine Situation ] | ||
| + | |||
| + | ==Online Books== | ||
| + | *[http://books.huihoo.org/introduction-to-information-retrieval/ Introduction to Information Retrieval] | ||
| + | *[http://books.huihoo.org/modern-information-retrieval Modern Information Retrieval] | ||
| + | ==图集== | ||
| + | <gallery> | ||
| + | image:apertis-search-flow.png|Apertis搜索 | ||
| + | </gallery> | ||
| − | == | + | ==链接== |
*Search Engine Watch - http://searchenginewatch.com/ | *Search Engine Watch - http://searchenginewatch.com/ | ||
*Search Tools - http://www.searchtools.com/ | *Search Tools - http://www.searchtools.com/ | ||
| 第82行: | 第150行: | ||
*Guidelines for Robot Writers : http://www.robotstxt.org/wc/guidelines.html | *Guidelines for Robot Writers : http://www.robotstxt.org/wc/guidelines.html | ||
*SearchTools.com: http://www.searchtools.com/robots/ ,All About Search Indexing Robots and Spiders | *SearchTools.com: http://www.searchtools.com/robots/ ,All About Search Indexing Robots and Spiders | ||
| + | *[http://www.opensearch.org OpenSearch] is a collection of simple formats for the sharing of search results. | ||
| + | *[http://www.infoq.com/cn/articles/recommendation-and-searchengine 推荐系统和搜索引擎的关系] | ||
| − | [[ | + | [[category:search engine]] |
| + | [[category:computer science]] | ||
2022年8月9日 (二) 10:11的最后版本
"聚类" 是目前搜索引擎最热门的技术。
"聚类" 主要分为"搜索内容聚类"和"搜索结果排序聚类"
搜索内容聚类:指基于内容方面的聚类
搜索结果排序聚类:主要体现在查询结果的排序上
国内著名搜索引擎公司百度总裁李彦宏说:搜索引擎不是人人都能做的领域,进入的门槛比较高。

搜索引擎的门槛主要是技术门槛,包括网页数据的快速采集、海量数据的索引和存储、搜索结果的相关性排序、搜索效率的毫秒级要求、分布式处理和负载均衡、自然语言的理解技术等等,这些都是搜索引擎的门槛。
搜索引擎的策略都是采用服务器群集和分布式计算技术。
经典文章: The Anatomy of a Large-Scale Hypertextual Web Search Engine

目录 |
[编辑] 搜索原理
| |
您可以在Wikipedia上了解到此条目的英文信息 Search engine Thanks, Wikipedia. |
主要做三个步骤:从互联网上抓取网页 → 建立索引数据库 → 在索引数据库中搜索排序。
从互联网上抓取网页——利用能够从互联网上自动收集网页的Spider系统程序,自动访问互联网,并沿着任何网页中的所有URL爬到其它网页,重复这过程,并把爬过的所有网页收集回来。建立索引数据库——由分析索引系统程序对收集回来的网页进行分析,提取相关网页信息(包括网页所在URL、编码类型、页面内容包含的关键词、关键词位置、生成时间、大小、与其它网页的链接关系等),根据一定的相关度算法进行大量复杂计算,得到每一个网页针对页面内容中及超链中每一个关键词的相关度(或重要性),然后用这些相关信息建立网页索引数据库。在索引数据库中搜索排序——当用户输入关键词搜索后,由搜索系统程序从网页索引数据库中找到符合该关键词的所有相关网页。因为所有相关网页针对该关键词的相关度早已算好,所以只需按照现成的相关度数值排序,相关度越高,排名越靠前。最后,由页面生成系统将搜索结果的链接地址和页面内容摘要等内容组织起来返回给用户。
[编辑] 搜索市场
据业内分析,今后以百度、Google和雅虎为主的水平搜索的增长将趋缓,而垂直搜索(手机移动搜索)、论坛搜索、本地搜索等未来新兴搜索引擎市场将以30%左右的速度增长,到2010年规模将达到78亿元。
也就是说,水平搜索风光不再,而垂直搜索则方兴未艾,垂直搜索是搜索市场新的“蓝海”。据市场研究机构Kelsey Group预测,在未来5年内,仅美国国内地区搜索市场规模将达34亿美元。
[编辑] 搜索历史
[编辑] 搜索引擎


- List of search engines
- Google - http://www.google.com
- Yahoo - http://search.yahoo.com
- http://www.chacha.com/
- http://www.clusty.com
- http://www.search.com
- Autonomy - http://www.autonomy.com.cn
- WiseNut - http://www.wisenut.com/
- MSN Search - http://search.msn.com
- A9 - http://www.a9.com
- Baidu - http://www.baidu.com
- Sogou
- Koders - Source Code Search Engine http://www.koders.com/
- Ask Jeeves - http://www.ask.com/
- Teoma - http://www.teoma.com/
- WiseNut - http://www.wisenut.com/
- Gigablast - http://www.gigablast.com/
- Creative Commons Search - http://search.creativecommons.org/
- Scrub The Web - http://www.scrubtheweb.com/
- FactBites.com - http://www.factbites.com
- Dumbfind - http://www.dumbfind.com/
- Entireweb - http://www.entireweb.com/
- Objects Search - http://www.objectssearch.com/
- Pipeline - http://www.pipeline-search.com/
- Mojeek - http://www.mojeek.com/
- Ulysseek - http://www.ulysseek.com/
- SearchHippo - http://www.searchhippo.com/
- Wotbox - http://www.wotbox.com/
- meta 搜索引擎 Myriad Search - http://www.myriadsearch.com/
- Majestic-12: Distributed Search Engine - 一个搜索引擎的协作项目
[编辑] 开源项目

[编辑] Spider
[编辑] Indexing
[编辑] C,C++
- Larbin
- Apache Lucene4c
- CLucene is a C++ port of Lucene - http://clucene.sourceforge.net
- SWISH++ - http://swishplusplus.sourceforge.net/
- ht://Dig
- Larbin
- mnoGoSearch - http://mnogosearch.org/
- Sphinx
- SF超高速FTP搜索引擎
- Aspseek - http://www.aspseek.org/
- OpenFTS - http://openfts.sourceforge.net/
- Swish-e - http://www.swish-e.org/
- OpenWebSpider - http://www.openwebspider.org/
- DataparkSearch - http://www.dataparksearch.org/
- Managing Gigabytes - http://www.cs.mu.oz.au/mg/
- Namazu(a Full-Text Search Engine) - http://www.namazu.org/index.html.en (include perl)
- Zebra - http://indexdata.dk/zebra/
- Webglimpse - http://webglimpse.net/
- Xapian - http://www.xapian.org/
- Webbot
[编辑] Python
[编辑] Java
- Apache Lucene Search Engine (no crawler) - http://lucene.apache.org
- Apache Nutch (open source web-scalable search engine) - http://lucene.apache.org/nutch/
- Apache Hadoop - http://lucene.apache.org/hadoop/
- Heritrix
- Compass
- JXTA Search - http://search.jxta.org/
- XQEngine(XML Query Engine) - http://xqengine.sourceforge.net/
- Web-Harvest
- YaCy
[编辑] Ruby
[编辑] PHP
[编辑] Perl
[编辑] 中文资源
- 搜索引擎研究 - http://www.wespoke.com/
- 这就是搜索引擎:核心技术详解
[编辑] 相关文章
- Google的启示
- 中文分词和搜索引擎
- 中文搜索引擎技术揭密:中文分词
- 中文搜索引擎技术揭密:排序技术
- 中文搜索引擎技术揭密: 网络蜘蛛
- 中文搜索引擎技术揭密:系统架构
- 在 Linux 上构建 Web spider
- 中文/英文搜索引擎推广登录入口
- 2006chinese search engine Situation
[编辑] Online Books
[编辑] 图集
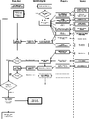
Apertis搜索

[编辑] 链接
- Search Engine Watch - http://searchenginewatch.com/
- Search Tools - http://www.searchtools.com/
- The Web Robots Pages : http://www.robotstxt.org/wc/robots.html ,一些很好的规则定义以及定义了Robots协议
- Guidelines for Robot Writers : http://www.robotstxt.org/wc/guidelines.html
- SearchTools.com: http://www.searchtools.com/robots/ ,All About Search Indexing Robots and Spiders
- OpenSearch is a collection of simple formats for the sharing of search results.
- 推荐系统和搜索引擎的关系