欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/ACL2, C++/F#/Lisp
Apache Hive
来自开放百科 - 灰狐
(版本间的差异)
小 (→链接) |
小 (→链接) |
||
| (未显示1个用户的22个中间版本) | |||
| 第2行: | 第2行: | ||
Apache Hive 是构建在[[Apache Hadoop]]之上的数据仓库基础设施,提供数据的汇总、查询和分析。 | Apache Hive 是构建在[[Apache Hadoop]]之上的数据仓库基础设施,提供数据的汇总、查询和分析。 | ||
| + | |||
| + | [[SQL on Hadoop]] | ||
| + | |||
| + | 替代方案:[[Apache Drill]]、[[Impala]] | ||
| + | |||
| + | ==简介== | ||
| + | [[Apache Spark]] 能替代 MapReduce 成为 Hive 的底层执行引擎。 | ||
| + | |||
| + | ==功能== | ||
| + | |||
| + | ==项目== | ||
| + | *[[Apache Druid]] | ||
| + | |||
| + | ==文档== | ||
| + | *[http://docs.huihoo.com/apache/apachecon/us2015/Hive-Now-Sparks.pdf Hive Now Sparks] | ||
| + | *[http://docs.huihoo.com/apache/apachecon/us2014/Interoperability-in-the-Apache-Hive-Ecosystem.pdf Interoperability in the Apache Hive Ecosystem] | ||
| + | *[http://docs.huihoo.com/apache/hadoop/apache-hadoop-hive-performance-2013.pdf Hive & Performance] | ||
| + | |||
| + | ==图集== | ||
| + | <gallery> | ||
| + | image:hue-hive-editor.png|Hive Editor | ||
| + | image:Hortonworks-Focus-for-Druid.png|Druid | ||
| + | image:Pre-Aggregate-into-Druid-using-Hive-SQL.png|集成Druid | ||
| + | image:Types-of-Analytics.png|分析类型 | ||
| + | image:Apache-Hive-LLAP-as-a-YARN-Service.png|Apache Hive LLAP | ||
| + | </gallery> | ||
==链接== | ==链接== | ||
*[http://hive.apache.org/ Apache Hive官网] | *[http://hive.apache.org/ Apache Hive官网] | ||
| + | *[https://github.com/apache/hive Apache Hive @ GitHub] | ||
| + | *[https://zh.hortonworks.com/blog/apache-hive-druid-part-1-3/ Ultra-fast OLAP Analytics with Apache Hive and Druid Part 1] ([https://zh.hortonworks.com/blog/sub-second-analytics-hive-druid/ Part 2], [https://zh.hortonworks.com/blog/connect-tableau-druid-hive/ Part 3]) | ||
| + | *[http://docs.huihoo.com/javadoc/apache/hive Hive Javadoc] | ||
| + | *[http://www.ibm.com/developerworks/cn/data/library/bd-hivewarehouse 使用 Hive 构建数据仓库] | ||
| + | *[https://zh.hortonworks.com/blog/stinger-next-enterprise-sql-hadoop-scale-apache-hive/ Stinger.next: Enterprise SQL at Hadoop Scale with Apache Hive] | ||
[[category:hadoop]] | [[category:hadoop]] | ||
| + | [[category:data warehouse]] | ||
[[category:apache]] | [[category:apache]] | ||
| + | [[category:hortonworks]] | ||
2021年8月18日 (三) 08:48的最后版本
| |
您可以在Wikipedia上了解到此条目的英文信息 Apache Hive Thanks, Wikipedia. |
Apache Hive 是构建在Apache Hadoop之上的数据仓库基础设施,提供数据的汇总、查询和分析。
替代方案:Apache Drill、Impala
目录 |
[编辑] 简介
Apache Spark 能替代 MapReduce 成为 Hive 的底层执行引擎。
[编辑] 功能
[编辑] 项目
[编辑] 文档
[编辑] 图集
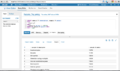
Hive Editor
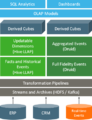
Druid
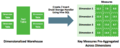
集成Druid

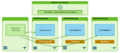
分析类型
Apache Hive LLAP




[编辑] 链接
分享您的观点