欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/ACL2, C++/F#/Lisp
Greenplum
小 |
小 (→新闻) |
||
| (未显示1个用户的38个中间版本) | |||
| 第1行: | 第1行: | ||
{{SeeWikipedia}} | {{SeeWikipedia}} | ||
| + | Greenplum | ||
| + | |||
| + | [[文件:greenplum-logo.png|right|Greenplum]] | ||
| + | |||
| + | ==简介== | ||
Greenplum数据引擎是为了支持新一代数据仓库和大规模分析处理而建立的软件解决方案。Greenplum支持SQL和[[MapReduce]]并行处理功能,并能以较低的成本向管理TB量级到PB量级数据的企业提供业界领先的性能. | Greenplum数据引擎是为了支持新一代数据仓库和大规模分析处理而建立的软件解决方案。Greenplum支持SQL和[[MapReduce]]并行处理功能,并能以较低的成本向管理TB量级到PB量级数据的企业提供业界领先的性能. | ||
Greenplum向企业提供了两种世界上最好的技术——针对程序员的MapReduce和针对数据库管理员的SQL——并且将直接在Greenplum的并行数据流引擎(位于Greenplum数据引擎的中心)内部直接执行MapReduce和SQL。 | Greenplum向企业提供了两种世界上最好的技术——针对程序员的MapReduce和针对数据库管理员的SQL——并且将直接在Greenplum的并行数据流引擎(位于Greenplum数据引擎的中心)内部直接执行MapReduce和SQL。 | ||
| − | + | ||
Greenplum MapReduce可以使程序员对储存在Greenplum数据引擎内部和外部的PB量级规模的数据集进行分析。Greenplum MapReduce带来的好处是一个不断增长的标准编程模型来满足关系数据库的可靠性和熟悉性。新的技术扩展了Greenplum数据引擎的功能,从而可以支持MapReduce程序。 | Greenplum MapReduce可以使程序员对储存在Greenplum数据引擎内部和外部的PB量级规模的数据集进行分析。Greenplum MapReduce带来的好处是一个不断增长的标准编程模型来满足关系数据库的可靠性和熟悉性。新的技术扩展了Greenplum数据引擎的功能,从而可以支持MapReduce程序。 | ||
了解下:[[Bizgres]] | 了解下:[[Bizgres]] | ||
| + | |||
==新闻== | ==新闻== | ||
| + | *Greenplum 已闭源,其 [https://github.com/greenplum-db/ GitHub] 仓库也已存档 | ||
| + | *[https://mp.weixin.qq.com/s/J_5dzhURpZpqUdp2iHzDpA 恭喜Pivotal上市,我们来梳理一下Pivotal的前世今生] (2018.04) | ||
*[https://github.com/greenplum-db/gpdb Greenplum以Apache v2开放源代码 (201510)] | *[https://github.com/greenplum-db/gpdb Greenplum以Apache v2开放源代码 (201510)] | ||
| − | == | + | ==项目== |
| + | *[https://github.com/greenplum-db Pivotal Greenplum Database @ GitHub] | ||
| + | *[https://github.com/cloudberrydb/cloudberrydb Cloudberry Database] - Open source alternative to Greenplum Database. Created by the original Greenplum developers. | ||
| + | |||
| + | ==版本== | ||
| + | * 7.x | ||
| + | * 6.x | ||
| + | * 5.x | ||
| + | |||
| + | ==功能== | ||
*无共享海量并行处理架构 | *无共享海量并行处理架构 | ||
负责在一组机器上进行数据的分配和查询的并行执行。包括充分利用10个以上、100个以上或1000个以上处理器的能力,充分并行。 | 负责在一组机器上进行数据的分配和查询的并行执行。包括充分利用10个以上、100个以上或1000个以上处理器的能力,充分并行。 | ||
| 第28行: | 第45行: | ||
*标准SQL | *标准SQL | ||
| − | + | 完全支持ANSI SQL 2008标准和SQL OLAP 2003 扩展。所有的查询和执行都可以在系统内并行处理。 | |
*统一分析处理 | *统一分析处理 | ||
| 第65行: | 第82行: | ||
*行业标准接口 | *行业标准接口 | ||
支持标准数据库接口(SQL、ODBC、JDBC、DBI),可以和市场上领先的商业智能和提取/转换/导入(ETL)工具共同整合。 | 支持标准数据库接口(SQL、ODBC、JDBC、DBI),可以和市场上领先的商业智能和提取/转换/导入(ETL)工具共同整合。 | ||
| + | |||
| + | *多租户 | ||
| + | [https://digitx.cn/2018/05/15/greenplum_multi_tenancy/ 大数据云平台 Greenplum:多租户篇] Greenplum 支持的三种租户模型:一租户一数据库;一租户一名字空间(Schema/Namespace);全共享方式。 | ||
| + | |||
| + | *机器学习 | ||
| + | 内置[http://madlib.apache.org/ Apache MADlib]大数据机器学习引擎。 | ||
| + | |||
| + | ==指南== | ||
| + | [https://network.pivotal.io/products/pivotal-gpdb#/releases/6929/file_groups/694 Greenplum Database 5.0.0 Sandbox VM] | ||
| + | |||
| + | 下载[https://github.com/greenplum-db/gpdb-sandbox-tutorials Greenplum虚拟机],开始体验。 | ||
| + | |||
| + | ./start_all.sh 系统启动后, | ||
| + | Pivotal Greenplum Database Started on port 5432 | ||
| + | |||
| + | Pivotal Greenplum Command Center | ||
| + | http://localhost:28080 | ||
| + | gpmon/pivotal | ||
| + | Apache Zeppelin | ||
| + | http://localhost:8080 | ||
| + | |||
| + | ==Docker== | ||
| + | *[https://hub.docker.com/r/pivotaldata/centos-gpdb-dev/ CentOS image for GPDB development] | ||
| + | |||
| + | ==服务商== | ||
| + | *[http://www.vitessedata.com/ VitesseData/迅讯科技] | ||
| + | |||
| + | ==用户== | ||
| + | *[http://www.infoq.com/cn/news/2016/12/MySQL-PostgreSQL-Greenplum 在MySQL和PostgreSQL之外,为什么阿里要研发HybridDB数据库?] [https://github.com/aliyun/rds_dbsync dbsync 项目] | ||
==文档== | ==文档== | ||
*[http://docs.huihoo.com/greenplum/greenplum-zh-cn.pdf 新一代数据管理和数据分析解决方案] | *[http://docs.huihoo.com/greenplum/greenplum-zh-cn.pdf 新一代数据管理和数据分析解决方案] | ||
*[http://docs.huihoo.com/greenplum/greenplum-fundamentals.pdf Greenplum Fundamentals] | *[http://docs.huihoo.com/greenplum/greenplum-fundamentals.pdf Greenplum Fundamentals] | ||
| + | *[http://docs.huihoo.com/greenplum/Pivotal-Greenplum-Database-Overview-and-Demo.pdf Pivotal Greenplum Database Overview and Demo]、[http://docs.huihoo.com/greenplum/faa.tar.gz 下载Demo]、[https://github.com/greenplum-db/gpdb-sandbox-tutorials GitHub] | ||
| + | |||
| + | ==图集== | ||
| + | <gallery> | ||
| + | image:Greenplum-Command-Center-Dashboard.png|仪表盘 | ||
| + | image:Greenplum-Command-Center-System-Metrics.png|系统指标 | ||
| + | image:Greenplum-zeppelin.png|Zeppelin | ||
| + | image:greenplum-storage.png|多态存储 | ||
| + | image:madlib-architecture.png|MADlib | ||
| + | image:greenplum-multi-tenancy.jpg|多租户 | ||
| + | image:greenplum-multi-tenancy-sep-database.png|一租户一数据库 | ||
| + | image:greenplum-multi-tenancy-share-schema.png|一租户一名字空间 | ||
| + | image:greenplum-multi-tenancy-fullshare.png|全共享方式 | ||
| + | image:greenplum-multi-tenancy-resource-management.jpg|多租户资源管理 | ||
| + | image:greenplum-parallel-backups.jpg|并行备份 | ||
| + | image:greenplum-parallel-restores.jpg|并行恢复 | ||
| + | image:greenplum-non-parallel-restore-using-parallel-backup-files.jpg|非并行恢复 | ||
| + | image:greenplum-gptransfer-fast-mode.png|迁移数据快模式 | ||
| + | image:greenplum-gptransfer-slow-mode.png|迁移数据慢模式 | ||
| + | image:Deepgreen-DB-vs-Flavors-of-GPDB.png|Deepgreen DB | ||
| + | image:greenplum-parallel-dataflow.jpg|并行数据流引擎:MapReduce + SQL | ||
| + | </gallery> | ||
==链接== | ==链接== | ||
| − | * | + | *[https://greenplum.org/ Greenplum官网] |
| − | * | + | *[https://pivotal.io/ Pivotal] |
| − | *[http://docs.huihoo.com/greenplum Greenplum开放文档] | + | *[https://digitx.cn Digitx] |
| + | *[https://gp-docs-cn.github.io/ Greenplum数据库中文文档] | ||
| + | *[https://greenplum.cn/2019/07/05/greenplum-distributed-database-kernel-1/ Greenplum 分布式数据库内核揭秘(上篇)] [https://greenplum.cn/2019/07/07/greenplum-distributed-database-kernel-2/ Greenplum 分布式数据库内核揭秘(下篇)] | ||
| + | *[http://docs.huihoo.com/greenplum Greenplum开放文档]、[http://docs.huihoo.com/greenplum/pivotal/4.3.6/ Pivotal Greenplum Database 4.3.6 Documentation] | ||
| + | *[http://geek.csdn.net/news/detail/49960 开源大数据引擎:Greenplum 数据库架构分析] | ||
[[category:database]] | [[category:database]] | ||
| + | [[category:data warehouse]] | ||
| + | [[category:data analysis]] | ||
[[category:PostgreSQL]] | [[category:PostgreSQL]] | ||
[[category:big data]] | [[category:big data]] | ||
| + | [[category:machine learning]] | ||
2024年10月2日 (三) 11:27的最后版本
| |
您可以在Wikipedia上了解到此条目的英文信息 Greenplum Thanks, Wikipedia. |
Greenplum
目录 |
[编辑] 简介
Greenplum数据引擎是为了支持新一代数据仓库和大规模分析处理而建立的软件解决方案。Greenplum支持SQL和MapReduce并行处理功能,并能以较低的成本向管理TB量级到PB量级数据的企业提供业界领先的性能.
Greenplum向企业提供了两种世界上最好的技术——针对程序员的MapReduce和针对数据库管理员的SQL——并且将直接在Greenplum的并行数据流引擎(位于Greenplum数据引擎的中心)内部直接执行MapReduce和SQL。
Greenplum MapReduce可以使程序员对储存在Greenplum数据引擎内部和外部的PB量级规模的数据集进行分析。Greenplum MapReduce带来的好处是一个不断增长的标准编程模型来满足关系数据库的可靠性和熟悉性。新的技术扩展了Greenplum数据引擎的功能,从而可以支持MapReduce程序。
了解下:Bizgres
[编辑] 新闻
- Greenplum 已闭源,其 GitHub 仓库也已存档
- 恭喜Pivotal上市,我们来梳理一下Pivotal的前世今生 (2018.04)
- Greenplum以Apache v2开放源代码 (201510)
[编辑] 项目
- Pivotal Greenplum Database @ GitHub
- Cloudberry Database - Open source alternative to Greenplum Database. Created by the original Greenplum developers.
[编辑] 版本
- 7.x
- 6.x
- 5.x
[编辑] 功能
- 无共享海量并行处理架构
负责在一组机器上进行数据的分配和查询的并行执行。包括充分利用10个以上、100个以上或1000个以上处理器的能力,充分并行。
- 软件解决方案充分利用业界标准硬件
软件易于安装到来自一级厂商基于x86的业界标准服务器上,它在Linux 和 Solaris上都能运行。
- 容错和先进的复制机制
无单点故障。系统在内部利用日志转移和分级复制来实现冗余,并提供自动恢复。
- 线性的可扩展性
无共享体系结构和并行查询优化,确保性能和容量可以平滑地提高到100个以上的数据节点和1000个以上的处理器。
- MapReduce支持
MapReduce已经被谷歌和雅虎等互联网领先企业证明是一种大规模数据分析技术。Greenplum将这种能力提供给企业。
- 标准SQL
完全支持ANSI SQL 2008标准和SQL OLAP 2003 扩展。所有的查询和执行都可以在系统内并行处理。
- 统一分析处理
所有查询和分析(SQL、MapReduce、R等等)都在相同的并行数据流引擎上执行,使分析师、开发人员和统计人员运用共同的架构进行数据分析。
- 可编程并行数据分析
向数学家和统计人员提供新的并行能力的平台,支持研究、线性代数和机器学习。
- 数据库内部压缩
利用业界领先的压缩技术,以显著提高性能和减少所需空间来存储数据。客户可以看到磁盘空间会减少3-10倍,同时有效的I/O性能会相应增强。
- PB量级规模导入
在所有群集节点高性能地同时执行并行数据导入,速率超过4.5TB小时。
- 随时随地的数据存取
在数据引擎中,查询可以对于系统内还有系统外的数据来源进行分析并且返回答案,不论其所在地,格式,或存储介质。
- 动态扩张
使企业方便地大量或小量增加数据仓库容量,避免昂贵的设备或SMP服务器升级。
- 高级gNet互连技术
采用流水线技术和重新分配各节点的数据以实现复杂联结的高性能执行。
- 负载管理
允许管理员创建基于角色的资源管理列表,以队列分配资源和管理系统的负载。
- 集中管理
提供集群平台的管理工具和应用程序,使管理员管理多个数据库如同管理单一数据库。
- 性能监控
图形性能监控可以使用户监控运行情况和历史查询并跟踪系统的利用率和资源。
- 支持索引系统
Greenplum支持B-Tree、Hash、GiST和GIN等各种丰富的索引能力,确保数据工程师拥有实施最优设计所必要的工具。
- 行业标准接口
支持标准数据库接口(SQL、ODBC、JDBC、DBI),可以和市场上领先的商业智能和提取/转换/导入(ETL)工具共同整合。
- 多租户
大数据云平台 Greenplum:多租户篇 Greenplum 支持的三种租户模型:一租户一数据库;一租户一名字空间(Schema/Namespace);全共享方式。
- 机器学习
内置Apache MADlib大数据机器学习引擎。
[编辑] 指南
Greenplum Database 5.0.0 Sandbox VM
下载Greenplum虚拟机,开始体验。
./start_all.sh 系统启动后, Pivotal Greenplum Database Started on port 5432
Pivotal Greenplum Command Center
http://localhost:28080 gpmon/pivotal
Apache Zeppelin
http://localhost:8080
[编辑] Docker
[编辑] 服务商
[编辑] 用户
[编辑] 文档
[编辑] 图集
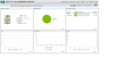
仪表盘
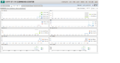
系统指标
Zeppelin

多态存储

MADlib

多租户
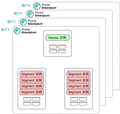
一租户一数据库
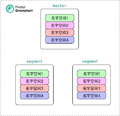
一租户一名字空间

全共享方式

多租户资源管理
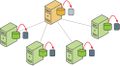
并行备份
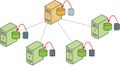
并行恢复
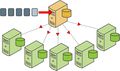
非并行恢复
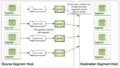
迁移数据快模式
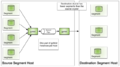
迁移数据慢模式

Deepgreen DB
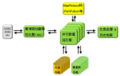
并行数据流引擎:MapReduce + SQL














