欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/ACL2/Agda, C++/Lisp/Haskell
Apache Spark
来自开放百科 - 灰狐
(版本间的差异)
小 (→项目) |
小 (→图集) |
||
| (未显示1个用户的1个中间版本) | |||
| 第1行: | 第1行: | ||
Apache Spark:新一代大数据解决方案 | Apache Spark:新一代大数据解决方案 | ||
| − | Spark 是用[[Scala]]语言编写的一套分布式内存计算系统,它的核心抽象模型是 RDD (Resilient Distributed Dataset,弹性分布式数据集),围绕 RDD 构建了一系列分布式 API,可以直接对数据集进行分布式处理。 | + | ==简介== |
| + | Spark 是用[[Scala]]和[[Java]]语言编写的一套分布式内存计算系统,它的核心抽象模型是 RDD (Resilient Distributed Dataset,弹性分布式数据集),围绕 RDD 构建了一系列分布式 API,可以直接对数据集进行分布式处理。 | ||
相对于 [[MapReduce]] 上的批量计算、迭代计算,以及基于 [[Apache Hive]] 的 SQL 查询,Spark 可以带来一到两个数量级的性能提升。 | 相对于 [[MapReduce]] 上的批量计算、迭代计算,以及基于 [[Apache Hive]] 的 SQL 查询,Spark 可以带来一到两个数量级的性能提升。 | ||
| 第101行: | 第102行: | ||
image:Berkeley-Data-Analytics-Stack.png|伯克利数据分析堆栈BDAS | image:Berkeley-Data-Analytics-Stack.png|伯克利数据分析堆栈BDAS | ||
image:baidu-spark-one.png|百度Spark One | image:baidu-spark-one.png|百度Spark One | ||
| + | image:hadoop-vs-spark.png|Hadoop vs Spark | ||
| + | image:Spark-Streaming.png|Spark Streaming | ||
</gallery> | </gallery> | ||
2022年4月20日 (三) 00:10的最后版本
Apache Spark:新一代大数据解决方案
目录 |
[编辑] 简介
Spark 是用Scala和Java语言编写的一套分布式内存计算系统,它的核心抽象模型是 RDD (Resilient Distributed Dataset,弹性分布式数据集),围绕 RDD 构建了一系列分布式 API,可以直接对数据集进行分布式处理。
相对于 MapReduce 上的批量计算、迭代计算,以及基于 Apache Hive 的 SQL 查询,Spark 可以带来一到两个数量级的性能提升。
Spark在广告领域有很多的成功应用。
[编辑] 版本
[编辑] Apache Hive
[编辑] Spark on HBase
- 使用 HDFS 内存层实现 RDD 共享
- Spark SQL on HBase: Spark SQL/DataFrame access to NoSQL data in Apache HBase
[编辑] Spark on YARN
通过Spark on YARN的方式与Apache Hadoop方便地共享集群的存储功能和计算资源。
[编辑] Cassandra
- Zen and the Art of Spark Maintenance
- DataStax Spark Cassandra Connector
- Installing the Cassandra / Spark OSS Stack
[编辑] elasticsearch
[编辑] REST API
Spark 1.4引入REST API
http://localhost:4040/api/v1/applications
[编辑] 机器学习
- MLbase
- Apache Mahout使用Spark作为后端
- Weka on Spark
- KeystoneML
- SparkNet
- CoCoA
- Splash Project for parallel stochastic learning
- Deeplearning4j
- H2O Spark
- TensorFlowOnSpark
- Yahoo CaffeOnSpark
- Arimo Tensorflow On Spark
[编辑] 项目
- Spark的相关项目和生态系统: Supplemental Spark Projects
- spark-jobserver
- SparkR
- Apache Mesos
- Alluxio
- FiloDB
- Apache Zeppelin, Spark Notebook
- SnappyData: OLTP + OLAP Database built on Apache Spark
- BlinkDB
- Spindle
- SpatialSpark
- Apache Toree
- Apache SystemML
- Oryx
- SnappyData OLTP + OLAP Database built on Apache Spark Efficient State Management With Spark 2.0 And Scale-Out Databases
- Livy an Open Source REST Service for Spark
[编辑] 服务商
- Spark背后的商业公司:Databricks,同时提供Spark服务提供商Certified Spark Distribution官方认证。
- Stratio Platform: The first "pure Spark" platform with 50% fewer components and operational complexity.
- IBM的思路是将Spark视为数据分析的操作系统。
[编辑] 用户
[编辑] 课程
[编辑] 文档
- Spark上的矩阵计算和神经网络
- Hive Now Sparks
- Going Deep with Spark Streaming
- Significantly Speed up real world big data Applications using Apache Spark
- Finding Shoe Stores in >100k Merchants: Using Spark to Group All Things
- Delivering Meaning In NearReal Time At High Velocity & Massive Scale
- Streaming OODT: Combining Apache Spark's Power with Apache OODT
- Machine learning in finance using Spark ML pipeline
- 在Spark上构建分布式神经网络
[编辑] 图集

Spark

Streaming
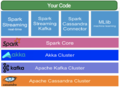
堆栈
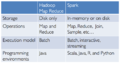
Spark和MapReduce
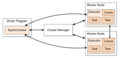
Spark集群

伯克利数据分析堆栈BDAS

百度Spark One

Hadoop vs Spark
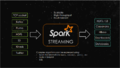
Spark Streaming








[编辑] 链接
- Apache Spark官网
- Spark @ GitHub
- Spark发源地:AMPLab
- UC Berkeley Big Data AMP Camp 大会资料
- Spark开放文档
- Spark Summit
- Spark Packages
- 腾讯大数据之计算新贵Spark,广点通是最早使用Spark的应用之一
- Spark在腾讯数据仓库TDW的应用
- 《Spark快速数据处理》作者 Holden Karau 曾就职于谷歌、亚马逊、微软和Foursquare等公司,对开源情有独钟,参与了许多开源项目,如Linux内核无线驱动、Android程序监控、搜索引擎等,对存储系统、推荐系统、搜索分类等都有深入研究。
- CSDN.NET Spark技术社区
- 理解Spark的核心Resilient Distributed Datasets(RDD)
- 七牛技术总监陈超:记Spark Summit China 2015
- 七牛是如何搞定每天500亿条日志的
- 39 Machine Learning Libraries for Spark
分享您的观点