欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/ACL2, C++/F#/Lisp
Hortonworks
来自开放百科 - 灰狐
(版本间的差异)
小 (→产品) |
小 (→图集) |
||
| (未显示1个用户的4个中间版本) | |||
| 第22行: | 第22行: | ||
*Hortonworks Data Platform (HDP) | *Hortonworks Data Platform (HDP) | ||
*Hortonworks DataFlow (HDF) 基于Apache NiFi,是专门用来解决数据采集,应对数据中心内外传输挑战的数据应用平台,可以从各种数据源(设备、企业应用程序、合作系统或边缘应用程序)提取数据,生成实时流数据。 | *Hortonworks DataFlow (HDF) 基于Apache NiFi,是专门用来解决数据采集,应对数据中心内外传输挑战的数据应用平台,可以从各种数据源(设备、企业应用程序、合作系统或边缘应用程序)提取数据,生成实时流数据。 | ||
| − | 整合 [[Apache NiFi]]、[[Apache Kafka]]、[[Apache Storm]]、[[Druid | + | 整合 [[Apache NiFi]]、[[Apache Kafka]]、[[Apache Storm]]、[[Apache Druid]] |
*[https://zh.hortonworks.com/products/data-platforms/cybersecurity/ Hortonworks Cybersecurity Platform (HCP)] | *[https://zh.hortonworks.com/products/data-platforms/cybersecurity/ Hortonworks Cybersecurity Platform (HCP)] | ||
| + | HCP 位于大数据和机器学习的主要交叉点,可帮助您获得单一风险视图、自动完成威胁检测和简化运营,从而克服安全运营的人员短缺问题。HCP 由 [[Apache Metron]] 提供支持,经过精确射击,能够大规模地将多样化的流式安全数据可视化,以帮助实时检测和应对威胁。 | ||
==项目== | ==项目== | ||
| 第32行: | 第33行: | ||
*[https://zh.hortonworks.com/apache/spark Spark is certified as YARN Ready and is a part of HDP] | *[https://zh.hortonworks.com/apache/spark Spark is certified as YARN Ready and is a part of HDP] | ||
*[https://zh.hortonworks.com/solutions/spark-at-scale/ Hortonworks提供用于企业部署的Spark] | *[https://zh.hortonworks.com/solutions/spark-at-scale/ Hortonworks提供用于企业部署的Spark] | ||
| − | + | *[https://zh.hortonworks.com/blog/distributed-pricing-engine-using-dockerized-spark-yarn-w-hdp-3-0-part-1-4/ Distributed Pricing Engine using Dockerized Spark on YARN w/ HDP 3.0 Part 1] ([https://zh.hortonworks.com/blog/distributed-pricing-engine-using-dockerized-spark-yarn-w-hdp-3-0-part-2-4/ Part 2], [https://zh.hortonworks.com/blog/distributed-pricing-engine-using-dockerized-spark-yarn-w-hdp-3-0-part-3-4/ Part 3], [https://zh.hortonworks.com/blog/distributed-pricing-engine-using-dockerized-spark-yarn-w-hdp-3-0-part-4-4/ Part 4]) | |
通过交付统一的 [[Apache Spark]] 和 Hadoop,我们将 Spark 驱动的敏捷分析工作流程与 Hadoop 的海量数据集和经济性相结合。借助 Hortonworks,企业可以使用行业最佳安全性、管制和运营能力来部署 Apache Spark。 | 通过交付统一的 [[Apache Spark]] 和 Hadoop,我们将 Spark 驱动的敏捷分析工作流程与 Hadoop 的海量数据集和经济性相结合。借助 Hortonworks,企业可以使用行业最佳安全性、管制和运营能力来部署 Apache Spark。 | ||
| 第40行: | 第41行: | ||
==EDW/BI== | ==EDW/BI== | ||
| − | [https://zh.hortonworks.com/solutions/edw-optimization/ EDW Optimization with Hadoop] | + | *[https://zh.hortonworks.com/solutions/edw-optimization/ EDW Optimization with Hadoop] |
| + | *[[SQL on Hadoop]] | ||
==用户== | ==用户== | ||
| 第137行: | 第139行: | ||
image:hortonworks-data-platform.png|HDP | image:hortonworks-data-platform.png|HDP | ||
image:Hortonworks-HDF-Data-in-Motion-Plaform.png|HDF | image:Hortonworks-HDF-Data-in-Motion-Plaform.png|HDF | ||
| + | image:HCP-real-time-processing-cyber-security-engine.png|HCP | ||
image:Data-Science-Lifecycle.png|数据科学生命周期 | image:Data-Science-Lifecycle.png|数据科学生命周期 | ||
image:hortonworks-sandbox-with-hdp-2.3.png|Hortonworks Sandbox | image:hortonworks-sandbox-with-hdp-2.3.png|Hortonworks Sandbox | ||
2018年11月25日 (日) 02:13的最后版本
| |
您可以在Wikipedia上了解到此条目的英文信息 Hortonworks Thanks, Wikipedia. |
Hortonworks:一家领先的大数据公司,拳头产品 Hortonworks Data Platform (HDP),Apache Hadoop 发行版。
Hortonworks 是 Apache Ambari 的主要贡献者。
目录 |
[编辑] 新闻
- The Forrester Wave™: Big Data Fabric, Q2 2018 (June 12, 2018)
- SequenceIQ is now a part of Hortonworks (April 13, 2015)
[编辑] 指南

通过Hortonworks Sandbox简单、快捷的体验Hadoop。
http://localhost:8888 raj_ops/raj_ops 或 maria_dev/maria_dev 或 amy_ds/amy_ds 或 holger_gov/holger_gov
重置admin密码
ssh [email protected] -p 2222 ambari-admin-password-reset ambari-agent restart
[编辑] 产品
- Hortonworks Data Platform (HDP)
- Hortonworks DataFlow (HDF) 基于Apache NiFi,是专门用来解决数据采集,应对数据中心内外传输挑战的数据应用平台,可以从各种数据源(设备、企业应用程序、合作系统或边缘应用程序)提取数据,生成实时流数据。
整合 Apache NiFi、Apache Kafka、Apache Storm、Apache Druid
HCP 位于大数据和机器学习的主要交叉点,可帮助您获得单一风险视图、自动完成威胁检测和简化运营,从而克服安全运营的人员短缺问题。HCP 由 Apache Metron 提供支持,经过精确射击,能够大规模地将多样化的流式安全数据可视化,以帮助实时检测和应对威胁。
[编辑] 项目
[编辑] Spark
- Spark is certified as YARN Ready and is a part of HDP
- Hortonworks提供用于企业部署的Spark
- Distributed Pricing Engine using Dockerized Spark on YARN w/ HDP 3.0 Part 1 (Part 2, Part 3, Part 4)
通过交付统一的 Apache Spark 和 Hadoop,我们将 Spark 驱动的敏捷分析工作流程与 Hadoop 的海量数据集和经济性相结合。借助 Hortonworks,企业可以使用行业最佳安全性、管制和运营能力来部署 Apache Spark。
[编辑] 数据科学
[编辑] EDW/BI
[编辑] 用户
[编辑] 文档
[编辑] 行业解决方案
- 挖掘 POS 数据来确定高价值购物者
- 让广告以特定文化或语言细分市场的客户为目标
- 根据行为、人口统计信息和渠道来组合视频
- 抽取、转换和加载(简称 ETL)玩具市场研究数据来实现更高的留客率和更深入的洞察力
- 优化零售网站的在线广告布置
- 筛选新帐户申请,避免违约风险
- 在次级市场中套现匿名银行数据
- 利用 Hadoop“星空图”保持次秒级 SLA
- 分析交易日志以检测洗钱活动
- 访问新癌症治疗的基因组数据
- 实时监管患者的生命体征
- 减少心脏病患者重新入院率
- 机器借助室内测试筛选孤独症患者
- 永久性存储医疗研究数据
- 借助 RFID 数据来跟踪设备、药物和护工
- 构建客户的全方位概览
- 通过统一代理商门户来提升代理商生产力
- 创建高速缓存以处理申请文档
- 检测欺诈
- 启动降低风险服务
- 借助实证传感器数据来为风险定价
- 确保准时交付原材料
- 采用实时和历史的组装线数据以实现质量控制
- 借助主动性设备维护来避免停工
- 提高制药产量
- 众包质量保证
- 智能仪表分析提高电网可靠性
- 单一资产视图,可优化电网运营
- 预测性设备维护,以防止停电
- 单一家庭视图,提供世界级客户服务
- 能源交易情报,在市场上领先一步
- 通过测井分析(也称为 LAS 分析)加速创新
- 定义每个井的操作设定点并在出现偏差时收到警报
- 借助可靠产量预测来优化租赁出价
- 通过靶向维护来预防性地修理设备
- 通过生产参数优化来减慢衰减
- 默克公司提高了疫苗产量:努力制造“黄金批次”
- 最大限度降低药品制造流程中的资源浪费
- 转化研究:将科学研究变成个体化药品
- 下一代测序
- HDP 使用真实数据来提供真实证据
- 在研究之前不间断访问原始数据
- 使用机器和传感器数据来主动维护公共基础设施
- 企业数据仓库最优化
- 大学健康关怀
- 防止欺诈和浪费
- 智能城市
- 资源的单一视图
- 构建客户的全方位概览
- 分析品牌情绪
- 促销本地化和个性化
- 优化网站
- 优化店铺布局
- 分析呼叫详细记录 (CDR)
- 主动维护设备
- 合理化基础设施投资
- 建议要购买的下一件产品 (NPTB)
- 实时分配带宽
- 开发新产品
[编辑] 图集

HDP

HDF

HCP
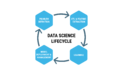
数据科学生命周期

Hortonworks Sandbox
用户
广告业
金融业
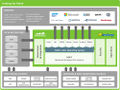
零售业
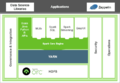
Spark

OpenShift
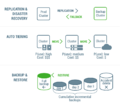
数据生命周期管理器 (DLM)
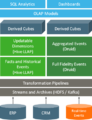
Druid
BI
DB2 Big SQL
混合架构
云解决方案
















[编辑] 链接
分享您的观点