欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/ACL2, C++/F#/Lisp
Machine learning on Hadoop
来自开放百科 - 灰狐
(版本间的差异)
小 (→链接) |
小 (→简介) |
||
| (未显示1个用户的6个中间版本) | |||
| 第1行: | 第1行: | ||
| − | [[Deep learning]] on [[ | + | [[Machine learning]] & [[Deep learning]] on [[Apache Hadoop]] |
| − | 在 HDP | + | ==简介== |
| + | 这里主要在[[Hortonworks]] (HDP & HDF & HCP) 上进行机器学习和深度学习。 | ||
| + | |||
| + | 在 HDP 上开发、部署、运营机器学习 & 深度学习软件基础设施,覆盖 Deep learning on hadoop, Deep learning on spark 等领域。 | ||
==好处== | ==好处== | ||
| 第10行: | 第13行: | ||
==指南== | ==指南== | ||
| + | *[https://zh.hortonworks.com/solutions/advertising/ Hadoop is Transforming Advertising] | ||
==项目== | ==项目== | ||
| 第15行: | 第19行: | ||
*[[Apache SINGA]] | *[[Apache SINGA]] | ||
*[[deeplearning4j]] | *[[deeplearning4j]] | ||
| − | *[[H2O]] | + | *[[H2O]] [https://h2o-release.s3.amazonaws.com/h2o/rel-ueno/6/docs-website/h2o-docs/hadoop.html H2O on Hadoop] |
*[[Keras]] | *[[Keras]] | ||
*雅虎[https://github.com/yahoo/CaffeOnSpark CaffeOnSpark]将深度学习带入Hadoop和Spark集群,[http://www.infoq.com/cn/news/2015/10/Hadoop-Caffe-Spark 雅虎如何在Hadoop集群上实现大规模分布式深度学习]。 | *雅虎[https://github.com/yahoo/CaffeOnSpark CaffeOnSpark]将深度学习带入Hadoop和Spark集群,[http://www.infoq.com/cn/news/2015/10/Hadoop-Caffe-Spark 雅虎如何在Hadoop集群上实现大规模分布式深度学习]。 | ||
*[[DMP on HDP]] | *[[DMP on HDP]] | ||
| + | *[[OpenAds]]和[[灰狐推荐]] | ||
==文档== | ==文档== | ||
| 第33行: | 第38行: | ||
image:Distributed-Deep-Learning-on-Hadoop.png|基于Hadoop的深度学习 | image:Distributed-Deep-Learning-on-Hadoop.png|基于Hadoop的深度学习 | ||
image:machine-learning-applied-to-big-data.jpg|机器学习应用于大数据 | image:machine-learning-applied-to-big-data.jpg|机器学习应用于大数据 | ||
| + | image:Baidu-spark-one.png|基于Spark的深度学习 | ||
</gallery> | </gallery> | ||
| 第42行: | 第48行: | ||
*[http://blog.cloudera.com/blog/2017/04/bigdl-on-cdh-and-cloudera-data-science-workbench/ BigDL: Distributed Deep Learning Library for Apache Spark] | *[http://blog.cloudera.com/blog/2017/04/bigdl-on-cdh-and-cloudera-data-science-workbench/ BigDL: Distributed Deep Learning Library for Apache Spark] | ||
| + | [[category:machine learning]] | ||
[[category:deep learning]] | [[category:deep learning]] | ||
[[category:hortonworks]] | [[category:hortonworks]] | ||
2018年11月9日 (五) 03:33的最后版本
Machine learning & Deep learning on Apache Hadoop
目录 |
[编辑] 简介
这里主要在Hortonworks (HDP & HDF & HCP) 上进行机器学习和深度学习。
在 HDP 上开发、部署、运营机器学习 & 深度学习软件基础设施,覆盖 Deep learning on hadoop, Deep learning on spark 等领域。
[编辑] 好处
在HDP(Hadoop)上进行深度学习主要有以下好处:
- 深度学习直接在Hadoop集群上执行,可以避免数据在Hadoop集群和单独的深度学习集群之间移动;
- 同Hadoop数据处理和Spark机器学习管道一样,深度学习也可以定义为Apache Oozie工作流中的一个步骤;
- YARN可以与深度学习很好地协同,深度学习的多个实验可以在单个集群上同时进行。与传统方法相比,这使得深度学习极其高效。
[编辑] 指南
[编辑] 项目
- BigDL
- Apache SINGA
- deeplearning4j
- H2O H2O on Hadoop
- Keras
- 雅虎CaffeOnSpark将深度学习带入Hadoop和Spark集群,雅虎如何在Hadoop集群上实现大规模分布式深度学习。
- DMP on HDP
- OpenAds和灰狐推荐
[编辑] 文档
- Deep Learning on HDP
- Machine Learning with Apache Spark
- NLP Structured Data Investigation on Non-Text
- Real Time Processing with Hadoop
- Operational Best Practices Workshop
- Perfect Together Spark + Hadoop
[编辑] 图集

GPU on YARN

基于Hadoop的深度学习
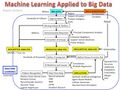
机器学习应用于大数据

基于Spark的深度学习




[编辑] 链接
分享您的观点