欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/Agda, C++/Erlang/Lisp
Apache Tika
来自开放百科 - 灰狐
(版本间的差异)
小 (→链接) |
|||
| (未显示1个用户的7个中间版本) | |||
| 第1行: | 第1行: | ||
| − | Apache | + | Apache Tika:通用的内容分析工具箱,通过现有的解析器库检测以及从各种文档提取元数据以及结构化的文本内容。 |
| − | + | Apache Tika 可以和 [[Apache Nutch]]、[[Apache Lucene]]、[[Apache Solr]] 结合,提供完整的搜索引擎基础设施。 | |
| − | [[ | + | ==图集== |
| − | [[ | + | <gallery> |
| + | image:apache-tika-framework.png|框架 | ||
| + | image:apche-tika-in-machine-learning.png|机器学习 | ||
| + | image:apache-tika-parser-method.png|Parse方法 | ||
| + | image:apache-tika-parser-interface-implementations.png|接口实现 | ||
| + | image:apache-nutch2-architecture.png|Nutch2框架 | ||
| + | image:apache-tika-metadata.png|元数据 | ||
| + | </gallery> | ||
| + | |||
| + | ==链接== | ||
| + | *[http://tika.apache.org/ Apache Tika官网] | ||
| + | *[http://www.ibm.com/developerworks/cn/opensource/tutorials/os-apache-tika/index.html 用 Apache Tika 理解信息内容] | ||
| + | *[http://blog.csdn.net/pelick/article/details/8520352 Apache Tika:通用的内容分析工具] | ||
| + | |||
| + | [[category:search engine]] | ||
| + | [[category:apache]] | ||
| + | [[category:metadata]] | ||
| + | [[category:OSGi]] | ||
2016年2月12日 (五) 00:41的最后版本
Apache Tika:通用的内容分析工具箱,通过现有的解析器库检测以及从各种文档提取元数据以及结构化的文本内容。
Apache Tika 可以和 Apache Nutch、Apache Lucene、Apache Solr 结合,提供完整的搜索引擎基础设施。
[编辑] 图集
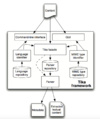
框架
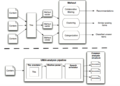
机器学习
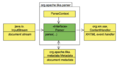
Parse方法
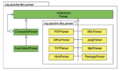
接口实现
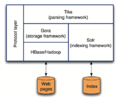
Nutch2框架
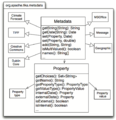
元数据






[编辑] 链接
分享您的观点