欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/ACL2/Agda, C++/Lisp/Haskell
Apache Impala
来自开放百科 - 灰狐
(版本间的差异)
小 (→链接) |
小 |
||
| 第1行: | 第1行: | ||
| + | Apache Implal: Real-time Query for [[Apache Hadoop]],是一个基于Hadoop的[[data warehouse|数据仓库]]解决方案。 | ||
| + | |||
Impala是由[[Cloudera]]开发,一个开源的Massively Parallel Processing(MPP)查询引擎 。与[[Apache Hive]]相同的元数据、SQL语法、ODBC驱动程序和用户接口(Hue Beeswax),可以直接在HDFS或HBase上提供快速、交互式SQL查询。 | Impala是由[[Cloudera]]开发,一个开源的Massively Parallel Processing(MPP)查询引擎 。与[[Apache Hive]]相同的元数据、SQL语法、ODBC驱动程序和用户接口(Hue Beeswax),可以直接在HDFS或HBase上提供快速、交互式SQL查询。 | ||
| 第22行: | 第24行: | ||
[[category:cloudera]] | [[category:cloudera]] | ||
[[category:c++]] | [[category:c++]] | ||
| + | [[category:apache]] | ||
2016年1月19日 (二) 02:02的版本
Apache Implal: Real-time Query for Apache Hadoop,是一个基于Hadoop的数据仓库解决方案。
Impala是由Cloudera开发,一个开源的Massively Parallel Processing(MPP)查询引擎 。与Apache Hive相同的元数据、SQL语法、ODBC驱动程序和用户接口(Hue Beeswax),可以直接在HDFS或HBase上提供快速、交互式SQL查询。
Impala是在Google Dremel的启发下开发的。
Impala不再使用缓慢的Hive+MapReduce批处理,而是通过与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或者HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。
文档
图集
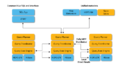
架构

链接
分享您的观点