欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/ACL2/Agda, C++/Lisp/Haskell
Apache Samza
来自开放百科 - 灰狐
(版本间的差异)
小 (→链接) |
小 (→链接) |
||
| 第28行: | 第28行: | ||
[[category:apache]] | [[category:apache]] | ||
[[category:kafka]] | [[category:kafka]] | ||
| + | [[category:scala]] | ||
2018年9月27日 (四) 09:07的最后版本
Apache Samza 是一个分布式流处理框架,基于 Apache Kafka 和 Apache Hadoop YARN 构建。
目录 |
[编辑] 指南
git clone https://git.apache.org/samza-hello-samza.git hello-samza cd hello-samza bin/grid bootstrap http://localhost:8088/
[编辑] 文档
[编辑] 用户
- Uber
- Netflix uses single-stage samza jobs to route over 700 billion events / 1 peta byte per day from fronting Kafka clusters to s3/hive. A portion of these events are routed to Kafka and ElasticSearch with support for custom index creation, basic filtering and projection. We run over 10,000 samza jobs in that many docker containers.
- 更多用户>>>
[编辑] 图集

生态
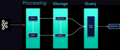
Uber流处理架构

[编辑] 链接
分享您的观点