欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/ACL2, C++/F#/Lisp
HPCC
| |
您可以在Wikipedia上了解到此条目的英文信息 HPCC Thanks, Wikipedia. |
HPCC
目录 |
新闻
- 庆祝为HPCC开源社区服务10年 (June 15, 2021)
简介
HPCC (High-Performance Computing Cluster), 也称为 DAS (Data Analytics Supercomputer) 是一个开源(Apache v2)的大数据处理和分析平台,使用 C++ 和 ECL 开发。
- 一套C++开发的大数据处理和分析平台;
- ECL (Enterprise Control Language) 和KEL (Knowledge Engineering Language) 是两个High Level的脚本语言;
- HPCC比Apache Hadoop历史更加悠久,在并行架构上也有自己的独到之处:Data Parallelism、Pipeline Parallelism、System Parallelism
版本
- 6.0.x
- 5.6.x
组件
HPCC Systems 包括以下核心组件:
- Thor (the Data Refinery Cluster)
- Roxie (Rapid Online XML Inquiry Engine, the Query Cluster)
- ECL (Enterprise Control Language)
- ECL IDE
- ESP (Enterprise Services Platform)
平行
Parallelism Architecture:
- Data Parallelism
- Component Parallelism
- Pipeline Parallelism
- System Parallelism
指南
下载 HPCC 虚拟机 快速启动。
http://127.0.0.1:8010/
HPCC配置管理器
sudo /opt/HPCCSystems/sbin/configmgr http://localhost:8015
机器学习
- Core ECL Machine Learning library ECL编写
- Machine Learning Library Reference
- Developing Machine Learning Algorithms on HPCC/ECL Platform
- Unsupervised Learning and Image Classification in High Performance Computing Cluster
- Optimizing Supervised Machine Learning Algorithms and Implementing Deep Learning in HPCC Systems
- Embedding TensorFlow Operations in ECL
Identity&Risk
- 2016 North American Healthcare Identity Management Technology Innovation Award
- Security and Privacy in a Big Data World
- Crowdsourcing large scale identity theft and fraud to make bucket loads of easy money
- Data Analytics Governance and Ethics
- Data Analytics in Cyber-Security and Threat Intelligence
可视化
HPCC Visualization Framework JavaScript编写
ECL
声明性的、模块化的、可扩展的企业控制语言(ECL)是专为处理大数据而设计的。ECL代码编译成优化的C++,并且可以利用C++库方便地扩展。
我可以写4行ECL代码来替代SQL中的200行。这使得阅读,理解和维护代码变得非常容易。- Adwait Joshi, DataSeers公司CEO
UDF
用户可通过Java, Python, C++ 和 R创建自己的User Defined Functions (UDF)。
ECL IDE
ECL Watch
ECL Watch 是运行在Enterprise Services Platform (ESP)的一个服务,是HPCC平台的一个中间件组件。
ECL Watch Candidate-6.4.0 源代码 JavaScript编写。
ESDL
ESDL (Enterprise Service Description Language)
SALT
SALT: Scalable Automated Linking Technology 提供:
- 连接和聚类 (MDM)
- 数据归档、清洗、规范、标准化
- 复杂的特性和基于连接和聚类的关系

Thor
Thor (the Data Refinery Cluster), Thor 集群负责复杂的数据处理。
Thor,数据提炼引擎,是提取和补充数据的引擎。
- Thor 使用主从拓扑,其从机提供本地化的数据存储和处理能力,主机监控和协调从机的活动,并传递任务状态信息。
- 中间组件提供命名服务和其它服务,以辅助执行分布式任务。
Roxie
Roxie (Rapid Online XML Inquiry Engine), ROXIE 集群负责数据查询和报告。
ROXIE,数据传送引擎,提供了高性能的在线处理和数据仓库功能。
- 每一个ROXIE节点会启动一个服务器进程和一个代理进程。这个服务器进程会处理用户传入的查询请求,并将查询任务分配给ROXIE集群相应的代理,校对结果,最后将有效负载返回给客户端。
- 查询可能包括数据联接和其它复杂数据转换,有效负载可以包含结构化或非结构化的数据。
Interlok
Interlok: Seamless Data Integration
KEL
KEL: Knowledge Engineering Language
社交图

ESP
ESP (Enterprise Services Platform)
DFS
分布式文件系统 (DFS)
- Thor DFS 是面向数据记录而设计的,并针对大数据ETL(提取-转换-加载) 进行了优化。数据记录存在于大数据输入文件中,可能是标准格式或是自定义格式,可能是定长或是不定长。大数据输入文件会在集群的 DFS 中进行分区,每一个节点都会获得大致相同数量的数据记录,并且单独记录不会被分割。
- ROXIE DFS 基于索引,并针对并发查询处理进行了优化。该系统基于自定义B+树结构,可以实现快速、高效的数据摄取。
Nagios
HPCC使用Nagios进行系统监控。
Ganglia
HPCC使用Ganglia提供监控和报表。
Hadoop
Cassandra
Kafka
AWS
用户
文档
- Introduction to HPCC
- ECL程序员中文指南
- ECL Programmers Guide
- ECL Best Practices
- ECL Language Reference 400多页
- ECL Standard Library Reference
- Dynamic ESDL (Enterprise Service Description Language)
- Installing & Running the HPCC Platform
图集

架构
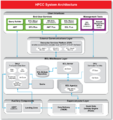
架构
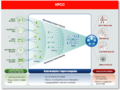
数据分析
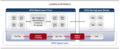
Lambda架构

Hadoop MapReduce
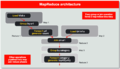
Pig
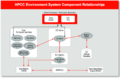
HPCC组件
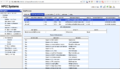
配置管理器
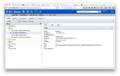
ECL Watch
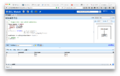
ELC操作平台
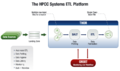
ETL平台

机器学习模块

Risk解决方案

HPCC用例

SALT方法
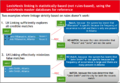
Linking方法












