欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/Agda, C++/Erlang/Lisp
Apache Kafka
小 (→服务商) |
小 |
||
| (未显示1个用户的3个中间版本) | |||
| 第1行: | 第1行: | ||
| − | Kafka 是一个高吞吐量的分布式消息系统,使用 [[Scala]] | + | Kafka 是一个高吞吐量的分布式消息系统,使用 [[Java]] 和 [[Scala]] 开发,早期由 [[LinkedIn]] 开发和内部使用。 |
| + | |||
| + | ==简介== | ||
| + | [http://www.infoq.com/cn/news/2017/10/Kafka-not-just-messag-system Kafka不只是个消息系统] | ||
Kafka 类似且堪比 Facebook [[Scribe]] 和 Cloudera [[Flume]] 系统。 | Kafka 类似且堪比 Facebook [[Scribe]] 和 Cloudera [[Flume]] 系统。 | ||
| 第5行: | 第8行: | ||
淘宝开源了分布式消息中间件[[Memorphosis]]项目,它是Kafka的Java版本,针对淘宝内部应用做了定制和优化。 | 淘宝开源了分布式消息中间件[[Memorphosis]]项目,它是Kafka的Java版本,针对淘宝内部应用做了定制和优化。 | ||
| − | == | + | ==功能== |
| − | + | Kafka 使用 [[Apache Avro|Avro]] 作为消息序列化框架,每天能高效处理数十亿级别的度量指标和用户活动跟踪信息。Kafka 使用 [[Apache ZooKeeper|ZooKeeper]] 保存集群的元数据信息和消费者信息。 | |
Kafka并非传统意义上的消息队列,它与[[RabbitMQ]]等消息系统并不一样。它更像是一个分布式的文件系统或数据库。Kafka与传统消息系统之间有三个关键区别: | Kafka并非传统意义上的消息队列,它与[[RabbitMQ]]等消息系统并不一样。它更像是一个分布式的文件系统或数据库。Kafka与传统消息系统之间有三个关键区别: | ||
| 第15行: | 第18行: | ||
以上三点足以将Kafka与传统的消息队列区别开,我们甚至可以把它看成是流式处理平台。 | 以上三点足以将Kafka与传统的消息队列区别开,我们甚至可以把它看成是流式处理平台。 | ||
| + | |||
| + | Kafka的解耦能力以及在安全和效率方面的可靠性,使它成为构建数据管道的最佳选择。常见的两种应用场景: | ||
| + | *把Kafka作为数据管道两个端点之一,如,把Kafka里的数据移动到S3上,或把[[MongoDB]]里的数据移动到Kafka里; | ||
| + | *把Kafka作为数据管道两个端点的中间媒介,如,为了把Twitter的数据移动到[[Elasticsearch]]上,需要先把数据移动到Kafka里,再将它们从Kafka移动到Elasticsearch上。 | ||
==新闻== | ==新闻== | ||
| 第146行: | 第153行: | ||
[[category:event]] | [[category:event]] | ||
[[category:LinkedIn]] | [[category:LinkedIn]] | ||
| + | [[category:java]] | ||
[[category:scala]] | [[category:scala]] | ||
[[category:big data]] | [[category:big data]] | ||
2020年11月12日 (四) 03:47的版本
Kafka 是一个高吞吐量的分布式消息系统,使用 Java 和 Scala 开发,早期由 LinkedIn 开发和内部使用。
目录 |
简介
Kafka 类似且堪比 Facebook Scribe 和 Cloudera Flume 系统。
淘宝开源了分布式消息中间件Memorphosis项目,它是Kafka的Java版本,针对淘宝内部应用做了定制和优化。
功能
Kafka 使用 Avro 作为消息序列化框架,每天能高效处理数十亿级别的度量指标和用户活动跟踪信息。Kafka 使用 ZooKeeper 保存集群的元数据信息和消费者信息。
Kafka并非传统意义上的消息队列,它与RabbitMQ等消息系统并不一样。它更像是一个分布式的文件系统或数据库。Kafka与传统消息系统之间有三个关键区别:
- Kafka持久化日志,这些日志可以被重复读取和无限期保留;
- Kafka是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过复制数据提升容错能力和高可用性;
- Kafka支持实时的流式处理。
以上三点足以将Kafka与传统的消息队列区别开,我们甚至可以把它看成是流式处理平台。
Kafka的解耦能力以及在安全和效率方面的可靠性,使它成为构建数据管道的最佳选择。常见的两种应用场景:
- 把Kafka作为数据管道两个端点之一,如,把Kafka里的数据移动到S3上,或把MongoDB里的数据移动到Kafka里;
- 把Kafka作为数据管道两个端点的中间媒介,如,为了把Twitter的数据移动到Elasticsearch上,需要先把数据移动到Kafka里,再将它们从Kafka移动到Elasticsearch上。
新闻
- Kafka迎来1.0.0版本,正式告别四位数版本号 (2017.11)
指南
tar -xzf kafka_2.11-0.9.0.0.tgz cd kafka_2.11-0.9.0.0 server.properties port = 9092 advertised.host.name = localhost bin/zookeeper-server-start.sh config/zookeeper.properties bin/kafka-server-start.sh config/server.properties
创建一个topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test bin/kafka-topics.sh --list --zookeeper localhost:2181
发送一些消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test This is a message This is another message
启动一个消费者consumer
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
分发版
- Confluent Platform
- Hortonworks Kafka
- IBM Message Hub Apache Kafka as a Service
项目
管理控制台
- Kafka Manager
- kafkat
- Hortonworks Streams Messaging Manager (SMM)
- Kafka Web Console 此项目已不再更新,请访问 Kafka Manager
git clone https://github.com/claudemamo/kafka-web-console cd kafka-web-console sbt > run http://localhost:9000
流处理
- Kafka Streams
- Apache Samza
- Storm Kafka spout
- kafka-storm-starter
- Apache Flink
- Apache Spark Streaming
- Apache Apex
集成Hodoop
搜索与查询
- kafka-elasticsearch-standalone-consumer
- Presto Kafka Connector
- Secor is a service persisting Kafka logs to Amazon S3, Google Cloud Storage and Openstack Swift
日志与监控
- Prometheus Kafka exporter
- syslog-gollector Go语言开发.
- Logging Utility & Daemon
- logkafka: Apache Kafka的日志收集代理 奇虎360开发
- Mozilla Metrics Service
- Coda Hale Metric Reporter to Kafka
Connect
存储
- Kafka Streams 使用 RocksDB 做 Local 存储。
文档
书籍
服务商
前LinkedIn首席工程师Jay Kreps和另两位Kafka创始成员共同创办了Confluent,和LinkedIn一道开发和维护Kafka,并提供商业化的支持订阅服务。
用户
- Powered By Kafka
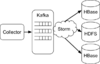
- Uber的流处理系统及实践 based on Apache Samza
- 七牛是如何搞定每天500亿条日志的
- 纽约时报在CMS系统里使用Kafka来保存他们的文章。
图集
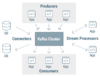
kafka
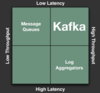
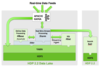
Kafka
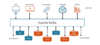
分布式流平台
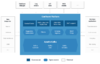
Confluent平台
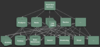
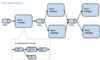
未使用Kafka
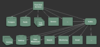
使用Kafka
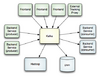
部署于LinkedIn
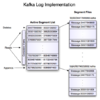
日志
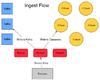
传感器数据
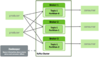
Broker
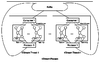
KStream架构
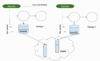
KStream状态
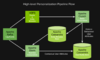
个性化推荐引擎
Kafka Manager
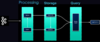
Uber流处理架构
Kafka Web Console

书籍














