欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/Agda, C++/Erlang/Lisp
Apache Nutch
来自开放百科 - 灰狐
(版本间的差异)
小 |
小 (→链接) |
||
| (未显示1个用户的5个中间版本) | |||
| 第16行: | 第16行: | ||
* 提供高质量的搜索结果 | * 提供高质量的搜索结果 | ||
* 以最小的成本运作 | * 以最小的成本运作 | ||
| + | |||
| + | ==简介== | ||
| + | Apache Nutch是一个高扩展、高伸缩的[[Web crawler|Web爬虫系统]]。 | ||
| + | |||
| + | Apache Nutch文件系统逐渐进化为后来的[[HDFS|Hadoop HDFS]]。 | ||
==版本== | ==版本== | ||
| 第21行: | 第26行: | ||
*Nutch1.2是一个完整的搜索引擎 | *Nutch1.2是一个完整的搜索引擎 | ||
*Nutch1.7是一个基于HDFS的网络爬虫 | *Nutch1.7是一个基于HDFS的网络爬虫 | ||
| − | *Nutch2.2. | + | *Nutch2.2.1是一个基于[[Apache Gora|Gora]]的网络爬虫 |
==开发人员== | ==开发人员== | ||
| 第27行: | 第32行: | ||
*http://www.frutch.org/ | *http://www.frutch.org/ | ||
| − | == | + | ==用户== |
[[Image:krugle_nutch.gif|right]] | [[Image:krugle_nutch.gif|right]] | ||
| − | [http://www.krugle.com/ Krugle]是一个建立在Nutch和 Lucene.基础上的,专门为程序员设计的搜索引擎帮助用户发现在线代码和技术信息。Krugle 的CEO Steve Larsen说:“没有 Nutch 和Lucene,我们不可能创建我们现在的搜索功能,也不可能拥有现在的速度……它们对于我们在短时间内解决技术问题极其重要。” | + | [https://wiki.apache.org/nutch/PublicServers Public search engines using Nutch] |
| + | *[http://www.krugle.com/ Krugle]是一个建立在Nutch和 Lucene.基础上的,专门为程序员设计的搜索引擎帮助用户发现在线代码和技术信息。Krugle 的CEO Steve Larsen说:“没有 Nutch 和Lucene,我们不可能创建我们现在的搜索功能,也不可能拥有现在的速度……它们对于我们在短时间内解决技术问题极其重要。” | ||
| + | *[https://www.openindex.io/index.html Openindex] Search as a Service & Crawl Solutions | ||
==图集== | ==图集== | ||
| 第39行: | 第46行: | ||
*[http://nutch.apache.org/ Apache Nutch官网] | *[http://nutch.apache.org/ Apache Nutch官网] | ||
*[http://wiki.apache.org/nutch/ Nutch Wiki] | *[http://wiki.apache.org/nutch/ Nutch Wiki] | ||
| + | *[http://docs.huihoo.com/javadoc/apache/nutch Nutch Javadoc] | ||
*http://wiki.media-style.com/display/nutchDocu/Home | *http://wiki.media-style.com/display/nutchDocu/Home | ||
*http://lucene.apache.org/hadoop/ | *http://lucene.apache.org/hadoop/ | ||
| − | + | [[category:web crawler]] | |
| − | + | ||
[[category:search engine]] | [[category:search engine]] | ||
| + | [[category:java]] | ||
[[category:apache]] | [[category:apache]] | ||
| + | [[category:huihoo]] | ||
2019年4月8日 (一) 01:32的最后版本
| |
您可以在Wikipedia上了解到此条目的英文信息 Apache Nutch Thanks, Wikipedia. |

Nutch 是一个刚刚诞生开放源代码(open-source)的web搜索引擎.
尽管Web搜索是漫游Internet的基本要求, 但是现有web搜索引擎的数目却在下降. 并且这很有可能进一步演变成为一个公司垄断了几乎所有的web搜索为其谋取商业利益.这显然不利于广大Internet用户.
Nutch为我们提供了这样一个不同的选择. 相对于那些商用的搜索引擎, Nutch作为开放源代码搜索引擎将会更加透明, 从而更值得大家信赖. 现在所有主要的搜索引擎都采用私有的排序算法, 而不会解释为什么一个网页会排在一个特定的位置. 除此之外, 有的搜索引擎依照网站所付的费用, 而不是根据它们本身的价值进行排序. 与它们不同, Nucth没有什么需要隐瞒, 也没有动机去扭曲搜索的结果. Nutch将尽自己最大的努力为用户提供最好的搜索结果.
Nutch 致力于让每个人能很容易, 同时花费很少就可以配置世界一流的Web搜索引擎. 为了完成这一宏伟的目标, Nutch必须能够做到:
- 每个月取几十亿网页
- 为这些网页维护一个索引
- 对索引文件进行每秒上千次的搜索
- 提供高质量的搜索结果
- 以最小的成本运作
目录 |
[编辑] 简介
Apache Nutch是一个高扩展、高伸缩的Web爬虫系统。
Apache Nutch文件系统逐渐进化为后来的Hadoop HDFS。
[编辑] 版本
Nutch 3大分支版本:
- Nutch1.2是一个完整的搜索引擎
- Nutch1.7是一个基于HDFS的网络爬虫
- Nutch2.2.1是一个基于Gora的网络爬虫
[编辑] 开发人员
[编辑] 用户

Public search engines using Nutch
- Krugle是一个建立在Nutch和 Lucene.基础上的,专门为程序员设计的搜索引擎帮助用户发现在线代码和技术信息。Krugle 的CEO Steve Larsen说:“没有 Nutch 和Lucene,我们不可能创建我们现在的搜索功能,也不可能拥有现在的速度……它们对于我们在短时间内解决技术问题极其重要。”
- Openindex Search as a Service & Crawl Solutions
[编辑] 图集
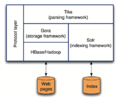
Nutch2框架

[编辑] 链接
分享您的观点