欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/ACL2/Agda, C++/Lisp/Haskell
Deeplearning4j
来自开放百科 - 灰狐
(版本间的差异)
小 (→链接) |
小 (→为何选择DL4J) |
||
| 第28行: | 第28行: | ||
*可在Hadoop、Spark上实现伸缩 | *可在Hadoop、Spark上实现伸缩 | ||
*[http://deeplearning4j.org/canova.html Canova]:机器学习库的通用向量化工具 | *[http://deeplearning4j.org/canova.html Canova]:机器学习库的通用向量化工具 | ||
| − | *[ | + | *[[ND4J]]:线性代数库,较[[Numpy]]快一倍 |
*[http://deeplearning4j.org/documentation 文档全面、有深度、多语言] | *[http://deeplearning4j.org/documentation 文档全面、有深度、多语言] | ||
2016年3月22日 (二) 10:44的版本
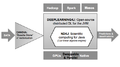
deeplearning4j:开源(Apache v2)神经网络平台,基于 Apache Hadoop, Apache Spark 构建,为 Java, Scala & Clojure 编程语言提供的深度学习库。
目录 |
应用场景
神经网络应用情景
DL4J神经网络
- 受限玻尔兹曼机
- 卷积网络(图像)
- 递归网络/LSTMs(时间序列和传感器数据)
- 递归自动编码器
- 深度置信网络
- 深度自动编码器(问-答/数据压缩)
- 递归神经传感器网络(场景、分析)
- 堆叠式降噪自动编码器
为何选择DL4J
为何选择Deeplearning4j?
- 功能多样的N维数组类,为Java和Scala设计
- 与GPU集合
- 可在Hadoop、Spark上实现伸缩
- Canova:机器学习库的通用向量化工具
- ND4J:线性代数库,较Numpy快一倍
- 文档全面、有深度、多语言
指南
推荐引擎
Build a Recommendation Engine With DL4J
Spark
- Deeplearning4j on Spark
- Iterative Reduce With DL4J on Hadoop and Spark
- How to Speed Up Spark With Native Binaries and OpenBlas
图集
DL4J

工业应用

DL4J UI

神经网络




链接
分享您的观点