欢迎大家赞助一杯啤酒🍺 我们准备了下酒菜:Formal mathematics/Isabelle/ML, Formal verification/Coq/Agda, C++/Erlang/Lisp
D3
小 (→运营) |
小 (→组成) |
||
| (未显示1个用户的110个中间版本) | |||
| 第2行: | 第2行: | ||
==含义== | ==含义== | ||
| − | + | D3:Data, [[Database]], [[Deep learning]] // 取其中的三个D | |
D3也表示以Data为中心的软件架构和开发模式。 | D3也表示以Data为中心的软件架构和开发模式。 | ||
| + | |||
| + | D3 is a Platform for Data. | ||
==愿景== | ==愿景== | ||
| − | + | 普适的[[big data|大数据]]和[[artificial intelligence|人工智能]],AI on every device everywhere. | |
| + | |||
| + | Build Your Own Data Cloud. | ||
==路线图== | ==路线图== | ||
| + | 缺省路线图:D3 [[Hortonworks|HDP]](两层含义:Huihoo Data Platform和Hortonworks Data Platform) | ||
| + | |||
路线一: | 路线一: | ||
| + | *基于[[Erlang]]数据库构建,Riak as a Foundation + [[Redis]] for Low Latency + [[Apache Spark|Spark]] for Analytics。(默认) | ||
| + | *[http://docs.huihoo.com/erlang/conference/euc2015/From-Concept-to-Reality-Solving-Enterprise-Challenges.pdf From Concept to Reality Solving Enterprise Challenges] | ||
| + | |||
| + | 路线二: | ||
| + | *做Python和数据分析发行版 D3 Analysis Platform(DAP),类似Anaconda。 | ||
| + | *[[Anaconda python|Anaconda]] D3 Anaconda Platform (DAP) + [https://pydata.org/ PyData] + [[scikit-learn]] + [[Keras]] [https://anaconda.org/omnia/keras conda install -c omnia keras=0.3.2] | ||
| + | |||
| + | 路线三: | ||
*以[[Hortonworks]]为大数据基石 | *以[[Hortonworks]]为大数据基石 | ||
*基于[[Deeplearning4j]]、[[H2O]]、[[Scala]]和[[Apache Spark]]构建[[Java virtual machine|JVM]]生态的D3解决方案:[[Deep learning on HDP]] | *基于[[Deeplearning4j]]、[[H2O]]、[[Scala]]和[[Apache Spark]]构建[[Java virtual machine|JVM]]生态的D3解决方案:[[Deep learning on HDP]] | ||
| 第16行: | 第30行: | ||
*Yahoo [https://github.com/yahoo/CaffeOnSpark CaffeOnSpark] | *Yahoo [https://github.com/yahoo/CaffeOnSpark CaffeOnSpark] | ||
*通过[[Apache Bigtop]]分发D3 | *通过[[Apache Bigtop]]分发D3 | ||
| − | + | ||
| + | 路线四: | ||
*[[HPCC]]是[[Apache Hadoop|Hadoop]]外的另一种选择。 | *[[HPCC]]是[[Apache Hadoop|Hadoop]]外的另一种选择。 | ||
*整合[[TensorFlow]], [[MXNet]], [[PaddlePaddle]]等深度学习框架和机器学习库。 | *整合[[TensorFlow]], [[MXNet]], [[PaddlePaddle]]等深度学习框架和机器学习库。 | ||
*[[C++]]语言核心驱动大数据和人工智能基础设施。 | *[[C++]]语言核心驱动大数据和人工智能基础设施。 | ||
*支持[[Python]]等尽可能多的外部接口语言。 | *支持[[Python]]等尽可能多的外部接口语言。 | ||
| − | + | [[文件:pydata.png|right]] | |
| − | + | ||
| − | + | ==核心== | |
| + | D3三驾马车:[[Apache Kafka]] Data Hub、[[Apache HBase]] Data Storage、[[Elasticsearch]] Data Insight. | ||
| + | |||
| + | ==堆栈== | ||
| + | D3软件堆栈:[[SMACK堆栈]] | ||
| + | |||
| + | ==商业形态== | ||
| + | 提供数据库、商业智能和数据分析服务 | ||
| + | |||
| + | [[灰狐数据]]: Huihoo Analytics | ||
| + | |||
| + | ==分析引擎== | ||
| + | Huihoo Analytics:基于 Analytical DBMS [https://github.com/yandex/ClickHouse ClickHouse] 构建,打造一套类似 [[Elasticsearch]] [https://www.elastic.co/cn/products/ Elastic Stack] 的解决方案。 | ||
==D3.NET== | ==D3.NET== | ||
| 第31行: | 第58行: | ||
==组成== | ==组成== | ||
| − | + | *D3 Studio(IDE) -> DStudio ? | |
| − | + | 可设计成类似 [https://apps.kde.org/cantor/ Cantor] 那样的数学和统计学工具包前端,支持 KAlgebra,Lua,Maxima,R,Sage,Octave,Python,Scilab 和 Qalculate 等众多环境 | |
| − | * | + | *D3 Server |
| − | + | *D3 Database | |
| − | + | ||
| − | * | + | |
| − | + | ||
工具 | 工具 | ||
| + | *D3 Studio based on [[Eclipse]] Data Tools Platform (DTP) 和 [[DBeaver]]/[[KNIME]] insprie by [[Metabase]] and [https://github.com/rapidminer/rapidminer-studio RapidMiner Studio] | ||
| + | *[[Anaconda python|Anaconda]] + [[Jupyter]] is the new front end for data science and AI. | ||
*打造成类似[[MATLAB]][[Machine_learning|机器学习]]和[[Artificial neural network|神经网络]]平台,基于[[GNU_Octave|Octave]]构建。 | *打造成类似[[MATLAB]][[Machine_learning|机器学习]]和[[Artificial neural network|神经网络]]平台,基于[[GNU_Octave|Octave]]构建。 | ||
| + | *De [[orange]] 数据挖掘工具包 | ||
*D3 [[weka]] 数据挖掘工具包 | *D3 [[weka]] 数据挖掘工具包 | ||
| + | |||
| + | 业务框架 | ||
| + | *[[Web crawler|网络爬虫]]、[[Search engine|搜索引擎]]、[[Natural language processing|自然语言处理]]提供的数据收集和数据挖掘服务。用[[elasticsearch]]驱动这一业务,它与[[Apache Hadoop]]有[https://github.com/elastic/elasticsearch-hadoop 深度整合] 提供[https://github.com/elastic/elasticsearch-py Python客户端] [https://github.com/elastic/elasticsearch-dsl-py DSL] 且有丰富的开源项目和商业模式。 | ||
| + | *将大数据和人工智能服务更好的支持业务发展,通过业务框架提供这一支撑。 | ||
| + | *[https://github.com/Tencent/mars Mars]微信官方的跨平台跨业务的终端基础组件可作为基础参考。[https://github.com/Tencent/weui/ WeUI] 为微信 Web 服务量身设计。 | ||
| + | |||
| + | 基础设施 | ||
| + | *[[PostgreSQL]] DBaaS, [https://github.com/citusdata/citus Citus] Multi-tenant database SaaS, [[OpenStack/trove|OpenStack DBaaS (Trove)]] 数据库即服务,跟进[[Amazon Aurora]]。 | ||
| + | *[[Deep learning on HDP]] [http://docs.huihoo.com/hortonworks/deep-learning-with-hortonworks-and-apache-spark.pdf Deep Learning on HDP] | ||
| + | *[[HDP on OpenStack]] | ||
==数据== | ==数据== | ||
| 第47行: | 第84行: | ||
*通过[[scrapy]]等工具爬取更多数据 | *通过[[scrapy]]等工具爬取更多数据 | ||
| − | == | + | ==数据库== |
| − | [[ | + | D3 Studio 客户端管理工具,基于 [[SQuirreL_SQL_Client]] 构建,支持 [[MariaDB]]、[[PostgreSQL]]、[[Apache Cassandra]]、[[MongoDB]]、[[ArangoDB]]等数据库。 |
| − | + | 为 [[RavenDB]]、[[PostgreSQL]]、[[MariaDB]] 和 [[ScyllaDB]] 等核心数据库提供支持和服务,D3 [[DBeaver]] 的分发。 | |
| − | [[ | + | Multi-model is the future,以下是D3数据库路线图: |
| + | |||
| + | 喜欢 ArangoDB 的定位:One engine. One query language. Multiple models. | ||
| + | |||
| + | D3 [[ArangoDB]]多模型(Multi-model)数据库,Apache v2。 | ||
| + | |||
| + | [https://github.com/ngaut/builddatabase 从零开始写分布式数据库] 一个思路 | ||
| + | |||
| + | D3 database基于[[Riak]]构建和分发: | ||
| + | *D3 KV | ||
| + | *D3 TS | ||
| + | *D3 S2 | ||
| + | |||
| + | D3 PostgreSQL分发版,based on [[CitusDB]],[[PostgreSQL]] as a Service,PSaaS。 | ||
| + | |||
| + | 数据库集群: | ||
| + | D3 Cluster based on [[Vitess MySQL Cluster]] | ||
| + | *D3 [[RavenDB]] | ||
| + | *D3 [[ScyllaDB]] | ||
| + | *D3 Cluster for MariaDB (容器集群) | ||
| + | *D3 Cluster for PostgreSQL (容器集群) | ||
| + | *D3 MariaDB Cluster | ||
| + | *D3 PostgreSQL Cluster | ||
| + | *D3 ScyllaDB Cluster | ||
| + | |||
| + | ==数据库迁移== | ||
| + | *[https://datamigration.microsoft.com/ Azure Database Migration Guide] | ||
| + | |||
| + | ==数据库容器== | ||
| + | 容器持久化 | ||
| + | |||
| + | ==爬虫== | ||
| + | D3 Hawk 基于 [https://github.com/ferventdesert/Hawk Hawk] 一个桌面爬虫和 ELT 引擎,[[C Sharp|C#]] 编写。 | ||
| + | |||
| + | ==搜索引擎== | ||
| + | 信息检索 | ||
| + | *[[Apache Lucene]]、[[Apache Solr]]和[[Elasticsearch]]是我们在信息检索领域的工具集和兴趣所在。 | ||
| + | |||
| + | ==[[data science|数据科学]]== | ||
| + | 数据科学、[[Machine learning|机器学习]] | ||
| + | *D3V:基于 [https://antvis.github.io/ AntV] 和 [https://github.com/apache/incubator-echarts Apache ECharts] 的数据可视化 | ||
| + | *D3 [http://pnda.io/ PNDA] 大数据分析 | ||
| + | *D3 [[KNIME]] | ||
| + | *D3 [[H2O]] | ||
| + | *D3 [[orange]] 为数据挖掘提供一个更好用的机器学习软件包,而不总是[[SPSS]]。 | ||
| + | *D3 [[pentaho]] 数据集成、数据挖掘、大数据分析、商业智能解决方案。 | ||
| + | *[[Weka]]: [[Machine learning]] software to solve [[data mining]] problems | ||
| + | *[https://www.datacamp.com/community/podcast/women-in-data-science Women in Data Science] | ||
| + | |||
| + | ==科学计算== | ||
| + | 一个类似[[Anaconda python]]的[[Julia]]科学计算平台:D3 Julia。 | ||
| + | |||
| + | ==DC/OS== | ||
| + | D3 on DC/OS | ||
| + | |||
| + | [http://blog.huihoo.com/?p=958 Data Science and Machine Learning on DC/OS] | ||
| + | |||
| + | ==实践== | ||
| + | *[https://pypi.python.org/pypi PyPI] [https://github.com/pypa PyPA] [https://github.com/conda Conda]数据分析和包治理 | ||
==领域== | ==领域== | ||
*[[E3.NET|电商零售业]] | *[[E3.NET|电商零售业]] | ||
| + | *爬虫和搜索解决方案 Search as a Service | ||
| + | *[[Natural language processing|自然语言处理]] // 让D3更好的理解Web | ||
*[[计算广告]] | *[[计算广告]] | ||
| − | *[[Financial technology|金融服务]] | + | *[[Financial technology|金融服务/金融科技]] |
*[[Computer_vision|计算机视觉]]:[[Caffe]]2、[[DeepVC]] | *[[Computer_vision|计算机视觉]]:[[Caffe]]2、[[DeepVC]] | ||
*[[Autonomous car|自动驾驶汽车]] | *[[Autonomous car|自动驾驶汽车]] | ||
| + | *[[BigchainDB|区块链数据库]]和[[Blockchain|区块链]]数据市场 | ||
[[Hortonworks#.E8.A1.8C.E4.B8.9A.E8.A7.A3.E5.86.B3.E6.96.B9.E6.A1.88|>>>更多行业解决方案]] | [[Hortonworks#.E8.A1.8C.E4.B8.9A.E8.A7.A3.E5.86.B3.E6.96.B9.E6.A1.88|>>>更多行业解决方案]] | ||
| 第70行: | 第168行: | ||
*[[Apache Metron]] | *[[Apache Metron]] | ||
*[[H2O]] Flow | *[[H2O]] Flow | ||
| − | *[[Kettle]] | + | *[[Kettle]] & [[Talend]] |
*[[Apache Kylin]] [[OLAP]] on Hadoop | *[[Apache Kylin]] [[OLAP]] on Hadoop | ||
| − | *基于[[Eclipse]]的各种分析和运营工具:[[XMind]] | + | *基于[[Eclipse]]的各种分析和运营工具:[[KNIME]]、[[XMind]] |
| + | |||
| + | ==商业软件== | ||
| + | *[[SAS]] | ||
| + | *[[SPSS]] | ||
==图集== | ==图集== | ||
| + | <gallery> | ||
| + | image:Anaconda-Distribution.png|Anaconda Distribution | ||
| + | image:bigdata-v1.png|大数据 | ||
| + | image:pnda-console.png|PNDA | ||
| + | image:FDIO-Integrations.png|快数据 | ||
| + | image:aiven-io.png|Aiven | ||
| + | image:Basho-data-platform.png|Basho数据平台 | ||
| + | image:gekko-mongodb.png|比特币交易数据 | ||
| + | image:apache-madlib-architecture.png|MADlib架构 | ||
| + | </gallery> | ||
==链接== | ==链接== | ||
| + | *[https://www.growingio.com GrowingIO] 技术栈是 [[Scala]], [[play framework|Play]], [[Apache Spark|Spark]], [[Apache Kafka|Kafka]], [[Apache HBase|HBase]], [[ElasticSearch]] | ||
| + | *[https://www.analysys.cn/article/detail/1001275 Lambda架构已死,去ETL化的IOTA才是未来] | ||
[[category:big data]] | [[category:big data]] | ||
| + | [[category:fast data]] | ||
[[category:artificial intelligence]] | [[category:artificial intelligence]] | ||
[[category:deep learning]] | [[category:deep learning]] | ||
2023年7月19日 (三) 04:08的最后版本
D3
目录 |
[编辑] 含义
D3:Data, Database, Deep learning // 取其中的三个D
D3也表示以Data为中心的软件架构和开发模式。
D3 is a Platform for Data.
[编辑] 愿景
普适的大数据和人工智能,AI on every device everywhere.
Build Your Own Data Cloud.
[编辑] 路线图
缺省路线图:D3 HDP(两层含义:Huihoo Data Platform和Hortonworks Data Platform)
路线一:
- 基于Erlang数据库构建,Riak as a Foundation + Redis for Low Latency + Spark for Analytics。(默认)
- From Concept to Reality Solving Enterprise Challenges
路线二:
- 做Python和数据分析发行版 D3 Analysis Platform(DAP),类似Anaconda。
- Anaconda D3 Anaconda Platform (DAP) + PyData + scikit-learn + Keras conda install -c omnia keras=0.3.2
路线三:
- 以Hortonworks为大数据基石
- 基于Deeplearning4j、H2O、Scala和Apache Spark构建JVM生态的D3解决方案:Deep learning on HDP
- 以数据为中心的编程Clojure和分析平台Metabase,Clojure is about Data, Scala is about Types, Java is about Objects.
- Yahoo CaffeOnSpark
- 通过Apache Bigtop分发D3
路线四:
- HPCC是Hadoop外的另一种选择。
- 整合TensorFlow, MXNet, PaddlePaddle等深度学习框架和机器学习库。
- C++语言核心驱动大数据和人工智能基础设施。
- 支持Python等尽可能多的外部接口语言。

[编辑] 核心
D3三驾马车:Apache Kafka Data Hub、Apache HBase Data Storage、Elasticsearch Data Insight.
[编辑] 堆栈
D3软件堆栈:SMACK堆栈
[编辑] 商业形态
提供数据库、商业智能和数据分析服务
灰狐数据: Huihoo Analytics
[编辑] 分析引擎
Huihoo Analytics:基于 Analytical DBMS ClickHouse 构建,打造一套类似 Elasticsearch Elastic Stack 的解决方案。
[编辑] D3.NET
基于.NET的大数据和机器学习解决方案。
[编辑] 组成
- D3 Studio(IDE) -> DStudio ?
可设计成类似 Cantor 那样的数学和统计学工具包前端,支持 KAlgebra,Lua,Maxima,R,Sage,Octave,Python,Scilab 和 Qalculate 等众多环境
- D3 Server
- D3 Database
工具
- D3 Studio based on Eclipse Data Tools Platform (DTP) 和 DBeaver/KNIME insprie by Metabase and RapidMiner Studio
- Anaconda + Jupyter is the new front end for data science and AI.
- 打造成类似MATLAB机器学习和神经网络平台,基于Octave构建。
- De orange 数据挖掘工具包
- D3 weka 数据挖掘工具包
业务框架
- 网络爬虫、搜索引擎、自然语言处理提供的数据收集和数据挖掘服务。用elasticsearch驱动这一业务,它与Apache Hadoop有深度整合 提供Python客户端 DSL 且有丰富的开源项目和商业模式。
- 将大数据和人工智能服务更好的支持业务发展,通过业务框架提供这一支撑。
- Mars微信官方的跨平台跨业务的终端基础组件可作为基础参考。WeUI 为微信 Web 服务量身设计。
基础设施
- PostgreSQL DBaaS, Citus Multi-tenant database SaaS, OpenStack DBaaS (Trove) 数据库即服务,跟进Amazon Aurora。
- Deep learning on HDP Deep Learning on HDP
- HDP on OpenStack
[编辑] 数据
[编辑] 数据库
D3 Studio 客户端管理工具,基于 SQuirreL_SQL_Client 构建,支持 MariaDB、PostgreSQL、Apache Cassandra、MongoDB、ArangoDB等数据库。
为 RavenDB、PostgreSQL、MariaDB 和 ScyllaDB 等核心数据库提供支持和服务,D3 DBeaver 的分发。
Multi-model is the future,以下是D3数据库路线图:
喜欢 ArangoDB 的定位:One engine. One query language. Multiple models.
D3 ArangoDB多模型(Multi-model)数据库,Apache v2。
从零开始写分布式数据库 一个思路
D3 database基于Riak构建和分发:
- D3 KV
- D3 TS
- D3 S2
D3 PostgreSQL分发版,based on CitusDB,PostgreSQL as a Service,PSaaS。
数据库集群: D3 Cluster based on Vitess MySQL Cluster
- D3 RavenDB
- D3 ScyllaDB
- D3 Cluster for MariaDB (容器集群)
- D3 Cluster for PostgreSQL (容器集群)
- D3 MariaDB Cluster
- D3 PostgreSQL Cluster
- D3 ScyllaDB Cluster
[编辑] 数据库迁移
[编辑] 数据库容器
容器持久化
[编辑] 爬虫
D3 Hawk 基于 Hawk 一个桌面爬虫和 ELT 引擎,C# 编写。
[编辑] 搜索引擎
信息检索
- Apache Lucene、Apache Solr和Elasticsearch是我们在信息检索领域的工具集和兴趣所在。
[编辑] 数据科学
数据科学、机器学习
- D3V:基于 AntV 和 Apache ECharts 的数据可视化
- D3 PNDA 大数据分析
- D3 KNIME
- D3 H2O
- D3 orange 为数据挖掘提供一个更好用的机器学习软件包,而不总是SPSS。
- D3 pentaho 数据集成、数据挖掘、大数据分析、商业智能解决方案。
- Weka: Machine learning software to solve data mining problems
- Women in Data Science
[编辑] 科学计算
一个类似Anaconda python的Julia科学计算平台:D3 Julia。
[编辑] DC/OS
D3 on DC/OS
Data Science and Machine Learning on DC/OS
[编辑] 实践
[编辑] 领域
- 电商零售业
- 爬虫和搜索解决方案 Search as a Service
- 自然语言处理 // 让D3更好的理解Web
- 计算广告
- 金融服务/金融科技
- 计算机视觉:Caffe2、DeepVC
- 自动驾驶汽车
- 区块链数据库和区块链数据市场
[编辑] 运营
- IPython Jupyter
- Apache Ambari Operational Best Practices Workshop
- Hue
- Apache Zeppelin
- Apache NiFi
- Apache Metron
- H2O Flow
- Kettle & Talend
- Apache Kylin OLAP on Hadoop
- 基于Eclipse的各种分析和运营工具:KNIME、XMind
[编辑] 商业软件
[编辑] 图集
Anaconda Distribution
大数据
PNDA

快数据

Aiven
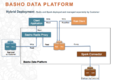
Basho数据平台
比特币交易数据

MADlib架构







